

Hi everyone-
Another month flies by – at least it finally seems to be getting a bit lighter in the mornings although I fear sunny spring days are still a way off… I imagine you are suffering withdrawal from a lack of dramatic Olympics Curling action so perhaps some thought provoking data science reading materials to fill the void…
Following is the March edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science March 2022 Newsletter
RSS Data Science Section
Committee Activities
We have all been shocked and saddened by events in the Ukraine and our thoughts and best wishes go out to everyone affected
The committee is busy planning out our activities for the year with lots of exciting events and even hopefully some in-person socialising… Watch this space for upcoming announcements.
We are very pleased to announce that Jennifer Hall, Senior AI Lab Data Scientist at NHSX and Will Browne, Associate Partner – Data Science & Analytics at CF Healthcare are both joining the Data Science and AI Section committee. They bring a wealth of talent and experience in all aspects of data science and we are very much looking forward to their contributions across our various activities.
Florian Ostmann has been involved with recent developments of the AI Standards Hub pilot (led by the Alan Turing Institute, in partnership with BSI and NPL)
Anyone interested in presenting their latest developments and research at the Royal Statistical Society Conference? The organisers of this year’s event – which will take place in Aberdeen from 12-15 September – are calling for submissions for 20-minute and rapid-fire 5-minute talks to include on the programme. Submissions are welcome on any topic related to data science and statistics. Full details can be found here. The deadline for submissions is 5 April.
Martin Goodson continues to run the excellent London Machine Learning meetup and is very active with events. The next one is on March 9th when Lucas Beyer, a Researcher at Google Brain Zurich, will discuss his research on “Learning General Visual Representations“. Videos are posted on the meetup youtube channel – and future events will be posted here.
Help RSS to support the data science community
The Royal Statistical Society (RSS) is developing resources to support everyone working in data science to meet their learning and development goals and career objectives. If you have an interest in data science, we invite you to take part in this survey, whether or not you are a member of RSS.
The survey should take around 15 minutes to complete. Your responses will be invaluable in helping us to understand and meet the wants and needs of the data science community, and to support your work in this exciting, fast-developing field.
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
- Boris Johnson’s reputation for truthfulness is not exactly high, but it is rare for a sitting prime minister to be rebuked for using the wrong figures by the official governmental agency…. As pointed out by a number of leading commentators the UK Stats Authority do not intervene lightly.
"The UK Statistics Authority have written to Downing St to advise them that the Prime Minister's claim that there are more people in work now than at the start of the pandemic is wrong. He has now made this claim 7 times but knows it is wrong! When will he correct the record?!."- Sadly the level of statistical literacy across UK politicians is not good, as recent RSS research has shown
"Those surveyed were asked: suppose there was a diagnostic test for a virus. The false-positive rate (the proportion of people without the virus who get a positive result) is one in 1,000. You have taken the test and tested positive. What is the probability that you have the virus? Of the politicians surveyed, 16 per cent gave the correct answer that there was not enough information to know."- Of course understanding official statistics is often not straightforward. It looks like the official ONS Excess Mortality figures will start to include 2021 figures into their baseline and so potentially look better than they are compared to the long run average.
- Over in the US, 3 Senators are looking to force the department of labor to move away from a third party identify verification provider (ID.me) because of privacy concerns.
- The Montreal AI Ethics Institute has been busy again, this time publishing their 6th “State of AI Ethics” report, a great summary of developments in many areas around the world.
- Interestingly China is at the forefront of some of these developments, as Wired digs into in this article
- Microsoft Research has an update on their approach to responsible AI research
The truth is AI failures are not a matter of if but when. AI is a human endeavor that combines information about people and the physical world into mathematical constructs. Such technologies typically rely on statistical methods, with the possibility for errors throughout an AI system’s lifespan. As AI systems become more widely used across domains, especially in high-stakes scenarios where people’s safety and wellbeing can be affected, a critical question must be addressed: how trustworthy are AI systems, and how much and when should people trust AI? - An extended piece in on the ‘duty of care’ the leading AI developers have with discussion from Safiya Umoja Noble (MacArthur Genius Fellowship recipient and an Associate Professor of Gender Studies and African American Studies at UCLA) and Meredith Whittaker (Faculty Director and cofounder of the AI Now Institute)
- Some interesting commentary from the Markup on why it is so hard to regulate algorithms
We found two key through lines: Lawmakers and the public lack fundamental access to information about what algorithms their agencies are using, how they’re designed, and how significantly they influence decisions.- Meanwhile, although leading autonomous driving companies continue to make progress, true self drive capabilities seem some way off as “Tesla recalls nearly 54,000 vehicles that may disobey stop signs“. Not surprisingly Elon Musk has a differing view
Tesla Chief Executive Officer Elon Musk said on Twitter "there were no safety issues" with the function. "The car simply slowed to ~2 mph & continued forward if clear view with no cars or pedestrians," Musk wrote.- Concerns over physical job losses to AI are surfacing are surfacing as advances in artificial intelligence and other technology allow machines to be operated from far away
- Elegant visual essay highlighting women’s under-representation in news headlines
- Some good news from OpenAI, where their new version of the ground breaking GPT-3 language model “produces less offensive language, less misinformation, and fewer mistakes overall” (more details here)
To train InstructGPT, OpenAI hired 40 people to rate GPT-3’s responses to a range of prewritten prompts, such as, “Write a story about a wise frog called Julius” or “Write a creative ad for the following product to run on Facebook.” Responses that they judged to be more in line with the apparent intention of the prompt-writer were scored higher. Responses that contained sexual or violent language, denigrated a specific group of people, expressed an opinion, and so on, were marked down. This feedback was then used as the reward in a reinforcement learning algorithm that trained InstructGPT to match responses to prompts in ways that the judges preferred.Developments in Data Science…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
- Some strong developments in the use of artificially generated faces to help improve facial recognition systems:
- Researchers at Microsoft have shown you can train models on synthetic data alone and generate strong results
- … and they have published their synthetic data set so anyone can have a go
- Of course generating synthetic faces that are indistinguishable from the real thing definitely has it’s downside with deep fake proliferation…
"Synthetically generated faces are not just highly photorealistic, they are nearly indistinguishable from real faces and are judged more trustworthy"- The researchers at Facebook/Meta have been busy:
- They have built their own super-computer, dubbed the AI Research Super Cluster...
- They have developed a Natural Language Processing (NLP) approach that does not use text or labels at all – it is able to learn directly from raw audio signals- pretty astonishing!
"GSLM leverages recent breakthroughs in representation learning, allowing it to work directly from only raw audio signals, without any labels or text. It opens the door to a new era of textless NLP applications for potentially every language spoken on Earth—even those without significant text data sets."- Not to be outdone, openAI has published more groundbreaking work:
- At face value, solving Maths Olympiad problems might not have ground breaking applications, but when you stop to think about what is going on, it is very impressive
- They have released Text and Code embeddings in the OpenAI- API based on a newer version of GPT-3, greatly simplifying semantic search, clustering and topic modelling, although some are less impressed with the results.
- A couple of excellent open source projects in the language model space we are big fans of and are keen to support:
- First of all Eleuther.AI has accomplished a lot in a short time, and their open source large language model (GPT-NeoX) is becoming increasingly impressive
- And then there is BigScience (https://bigscience.huggingface.co/)
- Google Research has been exploring generalisation of task learning in robots
“People can flexibly maneuver objects in their physical surroundings to accomplish various goals. One of the grand challenges in robotics is to successfully train robots to do the same, i.e., to develop a general-purpose robot capable of performing a multitude of tasks based on arbitrary user commands"- Continued progress in making Reinforcement Learning more efficient:
- Firstly, what feels like a sensible and intuitive approach to improving/speeding up reinforcement learning by allowing humans to nudge behaviour in the right direction.
- Then research into using Wikipeadia to help with offline RL
- Lots going on in AI vision research
- First of all improving training efficiency – “Training Vision Transformers with only 2040 images“
- Very cool- Waymo and Google Research working on large scale scene reconstruction from limited inputs (Block-NeRF)
- Pre-Training models on comparable readily available data is often a good way of building success when you have limited data sets – but how far can it go? Useful research exploring the limits of pre-training.
- Finally, how about Deep Physical Neural Networks!
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
- DeepMind is truly producing some astounding breakthroughs:
- Not stopping with solving the protein folding problem with AlphaFold they are now releasing estimated protein structures for free to researchers which is already driving crucial breakthroughs in medicine.
- Moving on from eternal health, to eternal energy, they have applied similar techniques to control superheated plasma inside a nuclear fusion reactor– excellent commentary from Wired and MIT Technology Review. In essence this turns nuclear fusion into a materials problem… which is also an area of fertile AI research.
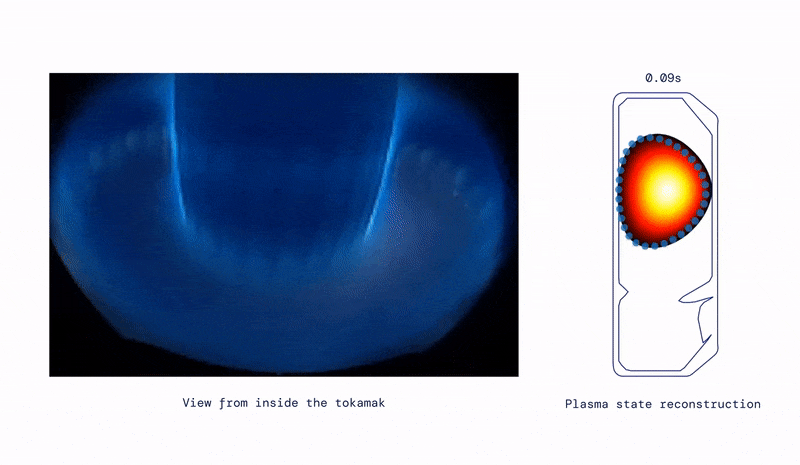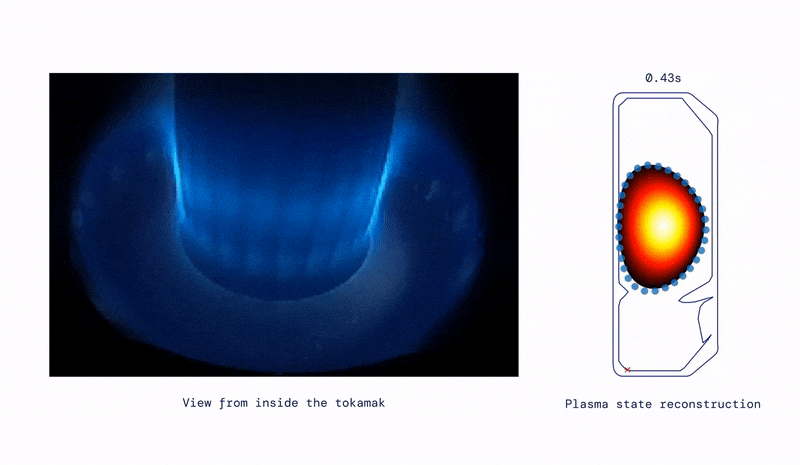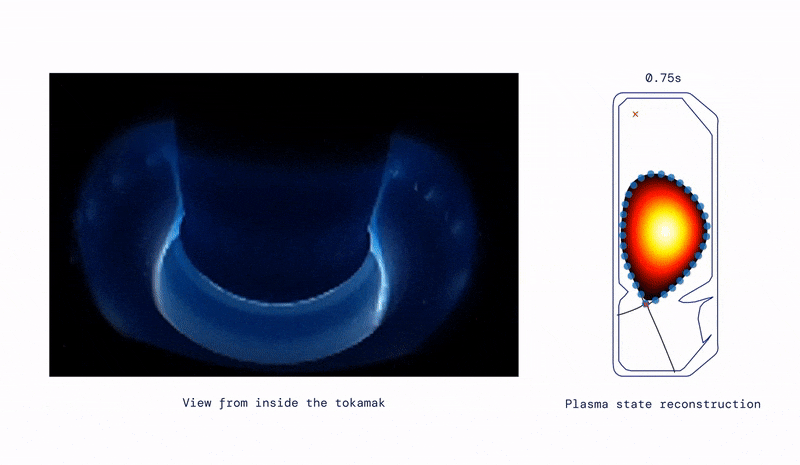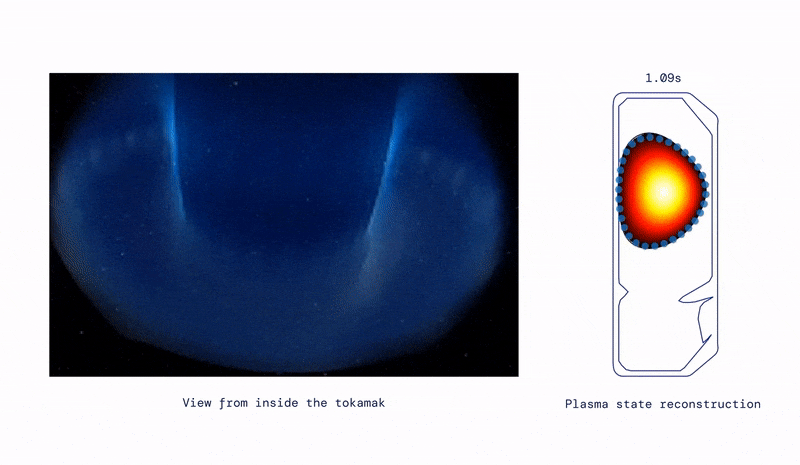
“It’s an incredibly powerful method,” says Jonathan Citrin at the Dutch Institute for Fundamental Energy Research, who was not involved in the work. “It’s an important first step in a very exciting direction.”- DeepMind also released AlphaCode which may put all us Data Scientists out of work sooner or later...
- Back to somewhat more mundane applications:
- Apple is experimenting with AI generated music
- And Sony has developed GT Sophy using Deep Reinforcement Learning – an AI that can take on all-comers at their famous Grand Turismo driving game.
“Outracing human drivers so skillfully in a head-to-head competition represents a landmark achievement for AI,” said Chris Gerdes, a professor at Stanford who studies autonomous driving, in an article published on Wednesday alongside the Sony research in the journal Nature.- Out in the big wide world, AI is helping in wildlife conservation, and making fruit and veg more tasty!
- And continuing work in healthcare diagnostics – this time in flagging potentially harmful treatments
"To help clinicians avoid remedies that may potentially contribute to a patient’s death, researchers at MIT and elsewhere have developed a machine-learning model that could be used to identify treatments that pose a higher risk than other options"How does that work?
A new section on understanding different approaches and techniques
- Firstly, the best deep learning training materials (from the University of Amsterdam) according to a well respected guru (thanks Martin!…)
- Useful step by step tutorial on transfer learning
- Voice Activity Detection – a core algorithm at the heart of Automatic Speech Recognition
- Excellent tutorial on Transformers from Hugging Face
- Background on econometrics and AI for economics
- More useful materials and tutorials on JAX
- Algorithms can be a somewhat neglected area in a data scientists skill-set, but are very useful, particularly in optimisation work – here is good step by step explanation of the A* Algorithm for graph search
"A* is a modification of Dijkstra’s Algorithm that is optimized for a single destination. Dijkstra’s Algorithm can find paths to all locations; A* finds paths to one location, or the closest of several locations. It prioritizes paths that seem to be leading closer to a goal."- “The art of solving problems with Monte Carlo simulations” – if you need a brush up probability in general, this looks useful
- Finally … ever heard of vector databases? me neither, but interesting concept
"Vector databases are purpose-built to store, index, and query across embedding vectors generated by passing unstructured data through machine learning models."Practical tips
How to drive analytics and ML into production
- Excellent in-depth discussion of data distribution drifts and how to combat them from Chip Huyen
- Elegant approach to model explainability – datamodels
- Should you package up your code? Broadly … yes!
- More background on testing best practice for data science and machine learning
- Python slicing best practices… always useful!
- Good DataExchange podcast interview with Savin Goyal at Netflix on the state of ML Infrastructure
- Finally, a different take on what data science courses should cover from Vin Vashishta (hat tip Ian Ozsvald and the NotANumber newsletter)
"Professor: “Yes, outstanding. However, you failed to ask me what metrics I used to grade your model. Your opinion of model quality doesn’t matter. It’s your users’ needs that do.”Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink!
- Andrew Gelman kicks things off with a thought provoking question: “What are the Most Important Statistical Ideas of the Past 50 Years?” (this was first published a couple of years ago but it is still very relevant)
"A lot has happened in the past half century! The eight ideas reviewed below represent a categorization based on our experiences and reading of the literature and are not listed in a chronological order or in order of importance. They are separate concepts capturing different useful and general developments in statistics."- There are lots of “here are all the problems with statistical significance” type articles out there, but the visual examples in this one make it more compelling than many

"You can have a miniscule effect size and still have a significant effect. Do we always prefer the (c) to the (a)? Is a meager, but mostly positive benefit necessarily better than a treatment potentially of large benefit to some but harmful to others necessarily? Wouldn’t it be in our interest to understand this spread of outcomes so we could isolate the group of individuals who benefit from the treatment?'”- “What the history of AI tells us about its future” – interesting historical background and commentary from MIT Technology Review
"So consider this Deep Blue’s final gift, 25 years after its famous match. In his defeat, Kasparov spied the real endgame for AI and humans. “We will increasingly become managers of algorithms,” he told me, “and use them to boost our creative output—our adventuresome souls.”- Yann Lecun talks to the “three big challenges” facing AI at the moment
But in the future, he says, systems will be needed that can handle all other scenarios as well: “It’s not just about the trajectory of a missile or the movement of a robotic arm, which can be modeled through careful mathematics. It’s about everything else, everything we observe in the world: About human behavior, about physical systems that involve collective phenomena like water or branches in a tree, about complex things for which humans can easily develop abstract representations and models,” LeCun saidBringing data to life – the art and science of visualisation
Leland Wilkinson, author of Grammar of Graphics, sadly passed away at the end of last year. Hadley Wickham created ggplot2 as a way to implement the ideas contained in this formative work (gg = grammar of graphics) and I know I for one have been heavily influenced by it in how I think about visualisation. In memory of Leland I thought it would be fitting to call out some recent articles of interest in the field.
- First of all, a memorial page at H20.ai, where he was Chief Scientist.
- Excellent article on precision vs expressiveness from Enrico Bertini – well worth a read
"The problem with guidelines based on precision is that visualization is not really about precision. Sure, there are cases where precision matters because it allows readers to detect important differences that would otherwise be missed. But visualization is less about precision, and much more about what the visual representation expresses."- “How to think less about data visualisation” from Allan Campopiano
- Geospatial visualisations can be so compelling as they convey many dimensions of information intuitively – hex tiles are a useful way of implementing these types of projects
- And sometimes custom is absolutely the way to go
- Less visualisation, more visual, but some interesting ideas on where AI can take us: recreating 70s Sci Fi book covers, and reimagining ancient birds…
Covid Corner
Well, apparently Covid is now all over according to the UK government, or at least there is no need for any more restrictions…
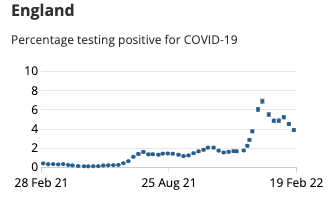
- Given the government is removing requirements and incentives to test for Covid, the ONS Coronavirus infection survey is now one of the only ways we can tell the prevalence of the virus in our society.
- The latest results estimate 1 in 25 people (4%) in England have Covid. While this is down from its peak of 1 in 15 in January it is still a long way from the 1 in 1000 we had last summer. Bear in mind in the chart below that the levels we had in February 2021 were enough to drive a national lockdown …
- Covid hospitalisations do seem to be falling but are still above the levels we had in December
- All this has led to a great deal of commentary questioning the decision to end all restrictions, from scientists (for example here, here and here) as well as political commentators.
Updates from Members and Contributors
- Jona Shehu and her colleagues at Helix Data Innovation are hosting what looks to be a high quality and relevant online roundtable on model explainability with leaders across the AI, finance, consumer rights and data governance sectors. The event is on March 15th (11-12.30) and is free to attend. Register here
- Kevin O‘Brien highlights the inaugural SciMLCon (of the Scientific Machine Learning Open Source Software Community) taking place online on Wednesday 23rd March 2022. Core topics include: Physics-Informed Model Discovery and Learning, Compiler-Assisted Model Analysis and Sparsity Acceleration, ML-Assisted Tooling for Model Acceleration and many more. SciMLCon is focused on the development and applications of the Julia-based SciML tooling -with expansion into R and Python planned in the near future.
- Maria Rosario Mestre is CEO of DataQA which offers tools to search, label and organise unstructured documents: sounds very useful! They are currently enrolling beta customers for the first release of the platform which includes a free trial so could be well worth checking out.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
- Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
- EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
- AstraZeneca are looking for a Data Science Training Developer – more details here
- Lloyds Register are looking for a data analyst to work across the Foundation with a broad range of safety data to inform the future direction of challenge areas and provide society with evidence-based information.
- Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
