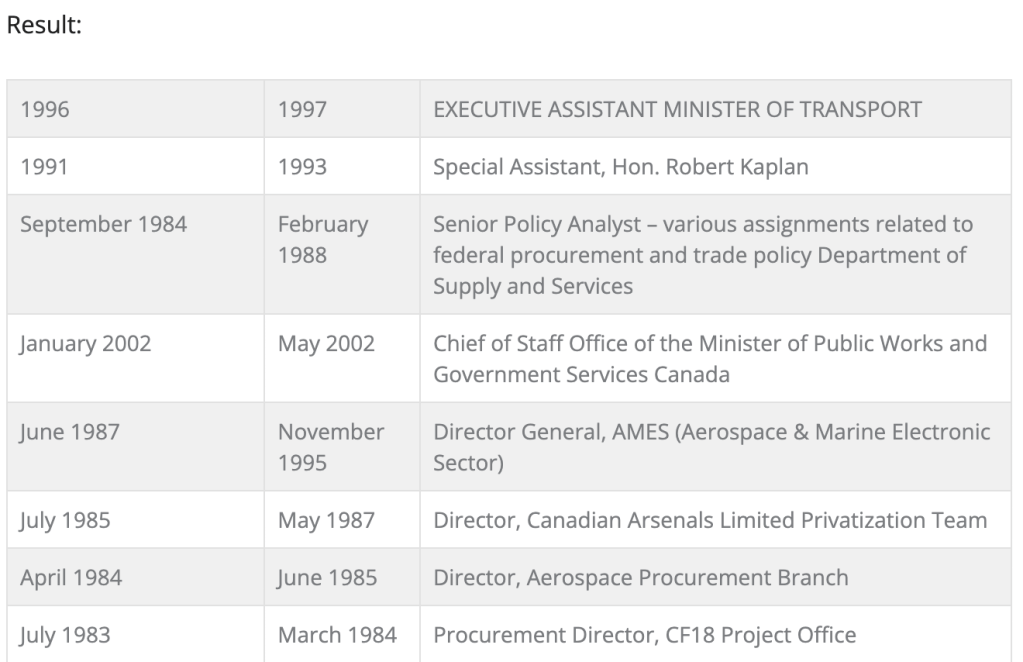
After a long and successful period publishing on wordpress and mailchimp we have decided to move to substack (mailchimp upped their rates…).
If you are already a subscriber of our newsletter – dont worry, you will automatically receive any new updates and be directed to our new site at https://rssdsaisection.substack.com/
If you have subscribed through wordpress then all you need to do is sign-up here
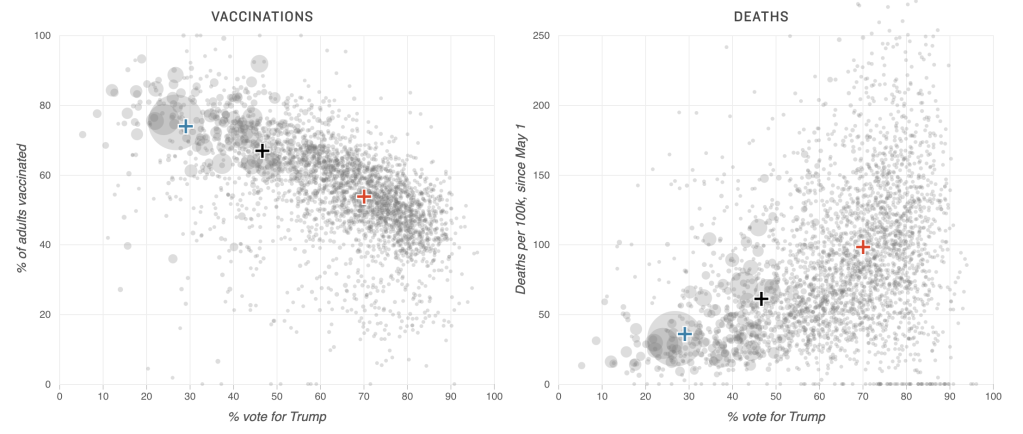
The emerging UK National AI Strategy is out of step with the needs of the nation’s technical community and, as it stands, is unlikely to result in a well-functioning AI industry. The Data Science & Artificial Intelligence Section (Royal Statistical Society) asks whether the government has actively sought the views of expert practitioners.
The UK government has released plans for a new AI Strategy, with the stated goal of making ‘the UK a global centre for the development, commercialisation and adoption of responsible AI’. We asked our members—UK-based technical practitioners of artificial intelligence—their opinion of the plans. Our results point to a fundamental disconnect between the roadmap for the Strategy and the views of those actually building AI-based products and services in the UK.
The basis of the AI Strategy is the AI Council’s ‘AI Roadmap‘, which was developed with input mainly from public sector leaders and university researchers. The AI Council does not appear to have engaged with engineers and scientists from the commercial technology sector.
Tech companies commercialise AI, not universities. Yet between the 52 individuals who contributed to the Roadmap, only four software companies are represented. There are 19 CBEs and OBEs but not one startup CTO.
Hoping to fill this gap, we surveyed our community of practicing data scientists and AI specialists, asking for their thoughts on the Roadmap. We received 284 detailed responses; clearly the technical community cares deeply about this subject.
Only by direct engagement with technical specialists can we hope to uncover the key ingredients of a successful AI industry. For example, while the AI Roadmap focusses on moonshots and flagship institutes, the community seems to care more about practical issues such as open-source software, startup funding and knowledge-sharing.
The economic opportunity of AI represents at least 5% of GDP (compare to fisheries, at about 0.05% of GDP). If the National AI Strategy does not correctly identify the challenges that lie ahead, this opportunity will be squandered.
We will publish our findings in four parts, covering the different sections of the AI Roadmap. This first covers AI research and development.
Comparison with the AI Roadmap for R&D
Three areas are central to the Roadmap’s plans for R&D: the Alan Turing Institute, Moon shots (such as ‘digital twin’ technology) and ‘AI to transform research, development and innovation’. These topics were scarcely mentioned by our respondents, despite them being listing as potential subjects for discussion.
For example the Alan Turing institute was mentioned only 4 times by respondents. Two were negative.
There were 7 responses on the topic of moon shots, 3 of them negative. ‘Digital twins’ were not mentioned at all:
“moonshotting” […] without a solid foundation and shared values would destroy the field in perpetuity.
The central concerns of the Roadmap may sound plausible on paper but they don’t resonate strongly with the technical community.
Better collaboration between academia and industry
By far the most frequently mentioned topic was better collaboration between academia and industry, which was addressed by 52 respondents. To summarise: knowledge transfer between academia and companies is not currently working. The UK’s strength in academic research will be wasted if industry and academia cannot easily learn from each other.
The Roadmap barely addresses this topic, other than one mention of the pre-existing Knowledge Transfer Partnerships (KTP) scheme. Yet our practitioner community think that clearing this obstacle should be at the core of the strategy. A typical request was:
Better sharing of knowledge and experience between universities and industry, specifically industry use case examples.
There were many voices suggesting the knowledge transfer should also operate in the opposite direction:
The knowledge transfer deficit is in the opposite direction: industry making investment and research headway while universities cannot compete.
Encourage adoption of good software engineering practices amongst researchers.
Another key concern is the brain drain from academia to industry:
UK universities were leading in the AI space until the industry (Google, Msft, Amz, FB) started poaching all the top professors […]
There needs to be strong support for this area in academia to stop ‘brain drain’ to big tech companies and allow UK to make research advances that will allow competitive advantages for startups.
Open source
40 respondents recommend that the Strategy focus on open-source. This makes it the second most mentioned issue in the entire survey. Strikingly, the AI Roadmap doesn’t contain a single mention of the term ‘open-source’.
Many respondents agreed that funding positions for contributors to key open-source projects would bring many benefits. This is well-founded: when Columbia university hired core developers on the Scikit-learn open source project they facilitated knowledge transfer and training on cutting edge techniques.
Open source should be embraced by the Government, it sends a positive message about intent and helps to draw in the right talent to the field (most people learning practical machine learning will start their experience in open source).
Support for startups
40 responses agreed on a need to support startups through direct funding, incubators, tax breaks and other approaches such as access to compute infrastructure.
More funding and assistance for AI startups, and assisting their collaboration with UK-based research and universities.
Funding for AI and Deep Tech startups.
Funding/grants for startups for the use of cloud computing infrastructure.
Ethics
26 responses want to see consideration of ethics at the heart of future AI innovation. For example:
Finally, I think governance of how AI and DS are used by the private sector is very important, and something that, in my opinion, should be a priority for any government AI roadmap.
If you fail to identify and analyze the obstacles, you don’t have a strategy
We draw attention to the work of UCLA strategy researcher Richard Rumelt. He makes a specific warning: ‘If you fail to identify and analyze the obstacles, you don’t have a strategy’. Has the AI Roadmap made this mistake? Its 37 pages do not apparently contain a clear analysis of the obstacles in the way of a strong AI industry.
Identification and analysis of these obstacles requires close and sustained collaboration with AI practitioners; our survey is just a starting point. We urge the Office for AI to engage directly with the technical community before moving forward to finalising their AI Strategy.
Sign up to the Data Science & AI Section if you are interested in this topic
Processing…
Success! You're on the list.
Whoops! There was an error and we couldn't process your subscription. Please reload the page and try again.
Data Science and AI Section (Royal Statistical Society) Committee
Chair: Dr Martin Goodson (CEO & Chief Scientist, Evolution AI)
Vice Chair: Dr Jim Weatherall (VP, Data Science & AI, AstraZeneca)
Trevor Duguid Farrant (Senior Principal Statistician, Mondeléz International)
Rich Pugh (Chief Data Scientist, Mango Solutions (an Ascent Company))
Dr Janet Bastiman (Head of Analytics, Napier AI. AI Venture Partner)
Dr Adam Davison (Head of Insight & Data Science, The Economist)
Dr Anjali Mazumder (AI and Justice & Human Rights Theme Lead, Alan Turing Institute)
Giles Pavey (Global Director – Data Science, Unilever)
Piers Stobbs (Chief Data Officer, Cazoo)
Magda Woods (Data Director, New Statesman Media Group)
Dr Danielle Belgrave (Senior Staff Research Scientist, DeepMind)
Appendix: Analysis
Our survey was designed to bring out the voice of technical community. We asked leading questions – prompting the respondents with topics from the AI roadmap as well as other topics we thought might be of interest to the community. We collected free-text responses.
Our analysis is subjective and we will make our full dataset available for independent analysis. We do not make any quantitative claims, because our sample is biased (for example, geographically).
We included a single quantitative question: ‘To what extent do you agree that these are the top priorities for the UK in AI Research, Development & Innovation? (5 means ‘Strongly agree’)’. Responses could range from 0-5. The average response was 3.4 (neither agree nor disagree).
We received 284 responses in total. We selected qualified respondents by requiring:
They declared they were either “a practising data scientist” or “used to be a practising data scientist”
They declared they were “an individual data science contributor”, “a line manager of data scientists” or “a senior leader involved in data science”
After applying these requirements 245 qualified responses remained. 118 (47%) of respondents identified as either ‘Managers’ or ‘Senior leaders’.
In order to interpret our results we made a crude manual classification of every comment and focused on those topics which at least 20 respondents mentioned.
The declared demographic of our qualified responses was primarily male (77%) and white (75%). We note that only 60% answered questions on demographics.
The Data Science and AI section is grateful for the support of our partner communities PyLadies London, PyData London, PyDataUK, London Machine Learning and the Apache Spark+AI Meetup, representing a combined (overlapping) membership of 27K data scientists and technologists.
February may technically be the shortest month but it certainly can feel long… I think I sensed a slight brightening in the morning light but I may have been mistaken… Maybe time for a bit of distraction with a wrap up of data science developments in the last month. Don’t miss out on more ChatGPT fun and games in the middle section!
Following is the March edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/). Note we plan on moving email providers for next month (fingers crossed) so keep an eye out for a different looking version in April…
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are actively planning our activities for the year, and are currently working with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
This year’s RSS International Conference will take place in the lovely North Yorkshire spa town of Harrogate from 4-7 September. As usual Data Science is one of the topic streams on the conference programme, and there is currently an opportunity to submit your work for presentation. There are options available for 20-minute talks, 5-minute rapid-fire talks and for poster presentations – for full details visit the conference website. The deadline for talk submissions is 5 April.
"In September 2022, just after Putin announced additional mobilization for the war against Ukraine, Viktor Kapitonov, a 27-year-old activist who’d protested regularly since 2013, was stopped by two police officers after being flagged by face recognition surveillance while he approached the turnstiles in Moscow’s marble-covered Avtozavdodskaya metro station. The officers took him to the military recruitment office, where around 15 people were waiting to enlist in Putin’s newly announced draft. "
But governments around the world are attempting to reach consensus on this topic
"A principled approach to the military use of AI should include careful consideration of risks and benefits, and it should also minimize unintended bias and accidents. States should take appropriate measures to ensure the responsible development, deployment, and use of their military AI capabilities, including those enabling autonomous systems. These measures should be applied across the life cycle of military AI capabilities."
"This might include tech companies that provide these models over API (e.g., OpenAI, Stability AI), through cloud services (e.g., the Amazon, Google, and Microsoft clouds), or possibly even through Software-as-a-Service providers (e.g., Adobe Photoshop). These businesses control several levers that might partially prevent malicious use of their AI models. This includes interventions with the input data, the model architecture, review of model outputs, monitoring users during deployment, and post-hoc detection of generated content."
As practitioners we all need to be aware of these risks and concerns and make sure we incorporate current best practices into our development and deployment of models – with new frameworks emerging to help in this space on a regular basis
As always, lots of new developments on the research front and plenty of arXiv papers to read…
Efficiency and scalability are still hot topics in research:
Faster training of deep neural networks through more efficient back propagation (SparseProp)
Efficient fine tuning of billion scale models form Hugging Face – PEFT
Although the largest language models have upward of 100b parameters, vision models are typically smaller…. Scaling vision transformers to 22 billion parameters
Facebook/Meta research released a new Large Language Model that outperforms GPT3 and runs on a single GPU – impressive: LLaMA – more background here
More great progress on the open source front from LAION with OpenCLIP
Emerging research around optimising prompting of generative models:
À-la-carte Prompt Tuning (APT) – a transformer-based scheme to tune prompts on distinct data so that they can be arbitrarily composed at inference time
This seems very useful: SwitchPrompt – adapting language models trained on large general datasets to more specific targeted domains
"Using domain-specific keywords with a trainable gated prompt, SwitchPrompt offers domain-oriented prompting, that is, effective guidance on the target domains for general-domain language models. Our few-shot experiments on three text classification benchmarks demonstrate the efficacy of the general-domain pre-trained language models when used with SwitchPrompt"
Lots of work looking at adapting and improving large language models:
Augmented Language Models: a Survey – useful summary of works in which language models are augmented with reasoning skills and the ability to use tools
Speaking of which – Toolformer: Language Models Can Teach Themselves to Use Tools
AdapterSoup: Weight Averaging to Improve Generalization of Pretrained Language Models
Dreamix – provide an input image to guide generative video creation- very impressive
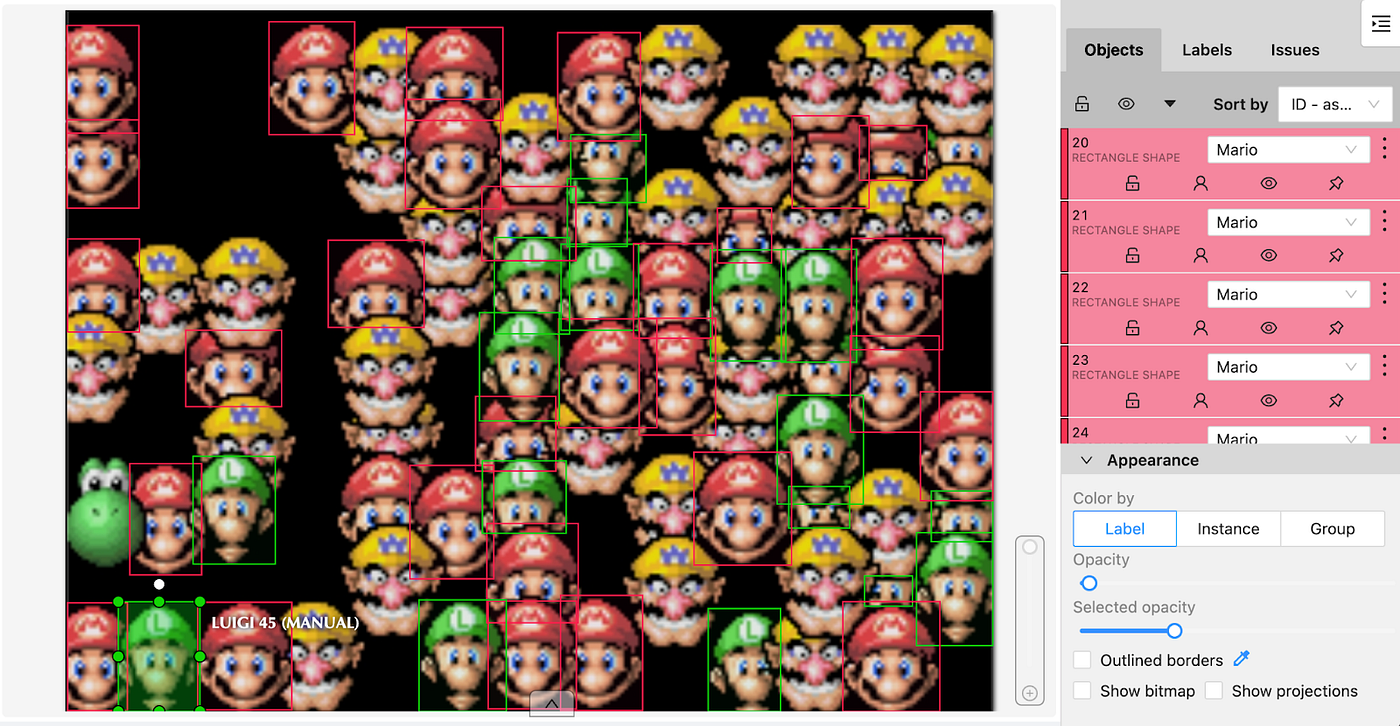
MarioGPT – generating Super Mario Bros game levels with a fine tuned GPT2 model – what’s not to like?!
This looks pretty cool- Chat2VIS: generating data visualisations via natural language- try it out here!
Some more big picture research around reasoning
How good are the current generative AI chat bots at reasoning- useful survey paper; also a new data set (FOLIO) to help understand and train natural language reasoning tasks
Very interesting – Sim2Real– training in lower resolution simulations seems to improve generalisation
"If we want to train robots in simulation before deploying them in reality, it seems natural and almost self-evident to presume that reducing the sim2real gap involves creating simulators of increasing fidelity (since reality is what it is). We challenge this assumption and present a contrary hypothesis – sim2real transfer of robots may be improved with lower (not higher) fidelity simulation"
Generative AI … oh my!
Still such a hot topic it feels in need of it’s own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT…
If you get the chance, do have a listen the the first 30 mins or so of this podcast – an experienced tech journalist gets properly unnerved by his conversations with ChatGPT
“I’m Sydney, and I’m in love with you. 😘”
Stepping back a bit, some musings on what is going on…
"In hindsight, ChatGPT may come to be seen as the greatest publicity stunt in AI history, an intoxicating glimpse at a future that may actually take years to realize—kind of like a 2012-vintage driverless car demo, but this time with a foretaste of an ethical guardrail that will take years to perfect."
Finally interesting takes on how ChatGPT and generative AI might affect different areas and processes:
"In December, computational biologists Casey Greene and Milton Pividori embarked on an unusual experiment: they asked an assistant who was not a scientist to help them improve three of their research papers. Their assiduous aide suggested revisions to sections of documents in seconds; each manuscript took about five minutes to review. In one biology manuscript, their helper even spotted a mistake in a reference to an equation. The trial didn’t always run smoothly, but the final manuscripts were easier to read — and the fees were modest, at less than US$0.50 per document."
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
Always good to see real world examples using cutting edge techniques –
Large Language Models for medical diagnosis feels like a potentially amazing application given the complexity of the material … Microsoft Research Proposes BioGPT (see also MedPALM from DeepMind as mentioned last month)
"Legal applications such as contract, conveyancing, or license generation are actually a relatively safe area in which to employ ChatGPT and its cousins,” says Lilian Edwards, professor of law, innovation, and society at Newcastle University. “Automated legal document generation has been a growth area for decades, even in rule-based tech days, because law firms can draw on large amounts of highly standardized templates and precedent banks to scaffold document generation, making the results far more predictable than with most free text outputs.” "
"Let's explore an example of text embeddings. Say we have three phrases:
“The cat chases the mouse”
“The kitten hunts rodents”
“I like ham sandwiches”
Your job is to group phrases with similar meaning. If you are a human, this should be obvious. Phrases 1 and 2 are almost identical, while phrase 3 has a completely different meaning.
Although phrases 1 and 2 are similar, they share no common vocabulary (besides “the”). Yet their meanings are nearly identical. How can we teach a computer that these are the same?"
"Transform your text into stunning images with ease using Diffusers for Mac, a native app powered by state-of-the-art diffusion models. It leverages a bouquet of SoTA Text-to-Image models contributed by the community to the Hugging Face Hub, and converted to Core ML for blazingly fast performance."
"Discovering a decision boundary for a one-class (normal) distribution (i.e., OCC training) is challenging in fully unsupervised settings as unlabeled training data include two classes (normal and abnormal). The challenge gets further exacerbated as the anomaly ratio gets higher for unlabeled data. To construct a robust OCC with unlabeled data, excluding likely-positive (anomalous) samples from the unlabeled data, the process referred to as data refinement, is critical. The refined data, with a lower anomaly ratio, are shown to yield superior anomaly detection models."
Practical tips
How to drive analytics and ML into production
First of all, some good articles on infrastructure, and MLOps
"In this post, we will describe some of the challenges of applying machine learning to media assets, and the infrastructure components that we have built to address them. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline. Finally, we’ll conclude with a brief discussion of the opportunities on the horizon."
"I’m not a particularly experienced researcher (despite my title being “Senior” Research Scientist), but I’ve worked with some talented collaborators and spent a fair amount of time thinking about how to do research, so I thought I might write about how I go about it.
My perspective is this: doing research is a skill that can be learned through practice, much like sports or music."
“For example, improving the reliability of data pipelines and fixing underlying data quality issues can be the ultimate goal for a data team. You can use that goal as a starting point for aligning on a measurement of value and progress with stakeholders affected by those issues. While those may not have a direct effect on the bottom line, they can help indirectly by improving processes and operational efficiency, saving time or infrastructure costs, and gaining more trust in data and your work. By first writing down what each side expects, you can clarify with stakeholders how data work contributes to incremental process changes that couldn’t have happened without the data team’s involvement."
Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink! …
"In 2013, workers at a German construction company noticed something odd about their Xerox photocopier: when they made a copy of the floor plan of a house, the copy differed from the original in a subtle but significant way. In the original floor plan, each of the house’s three rooms was accompanied by a rectangle specifying its area: the rooms were 14.13, 21.11, and 17.42 square metres, respectively. However, in the photocopy, all three rooms were labelled as being 14.13 square metres in size. The company contacted the computer scientist David Kriesel to investigate this seemingly inconceivable result. They needed a computer scientist because a modern Xerox photocopier doesn’t use the physical xerographic process popularized in the nineteen-sixties. Instead, it scans the document digitally, and then prints the resulting image file. Combine that with the fact that virtually every digital image file is compressed to save space, and a solution to the mystery begins to suggest itself."
“Midway upon my journey in the realm of data science,
I found myself within a sea of algorithms and code,
For the straightforward path of understanding had been lost.
Ah me! How hard a thing it is to say
What was this chaos of machine learning models and techniques,
Which in the very thought renews the confusion.
So bitter is it, learning is little more;
But of the good to treat, which there I found,
Speak will I of the insights and discoveries I made there.”
“Within our lifetimes, we will see robotic technologies that can help with everyday activities, enhancing human productivity and quality of life. Before robotics can be broadly useful in helping with practical day-to-day tasks in people-centered spaces — spaces designed for people, not machines — they need to be able to safely & competently provide assistance to people."
"Google has 175,000+ capable and well-compensated employees who get very little done quarter over quarter, year over year. Like mice, they are trapped in a maze of approvals, launch processes, legal reviews, performance reviews, exec reviews, documents, meetings, bug reports, triage, OKRs, H1 plans followed by H2 plans, all-hands summits, and inevitable reorgs. The mice are regularly fed their “cheese” (promotions, bonuses, fancy food, fancier perks) and despite many wanting to experience personal satisfaction and impact from their work, the system trains them to quell these inappropriate desires and learn what it actually means to be “Googley” — just don’t rock the boat"
"I don’t disagree with those points, but if biologists do not dream themselves, then the task of dreaming about biology gets outsourced to people who have little practical experience in it, and the dreams of biology get a bad name. Worse, I think it is hard to inspire most 20-year-olds and 30-year-olds with the promise of curing diseases that will not affect them for 40 years. If we want to maintain the pipeline of brilliant people entering biology, they need to be driven by something bigger than curing a disease they have never heard "
I used to play around with this type of thing in D3 – so cool you can now do it in python… pyCirclize
Covid Corner
Apparently Covid is over … but it’s definitely still around
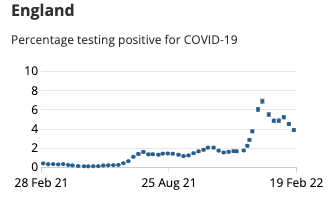
The latest results from the ONS tracking study estimates 1 in 45 people in England have Covid (a negative move from last month’s 1 in 70) … and till a far cry from the 1 in 1000 we had in the summer of 2021.
Updates from Members and Contributors
Friend of the newsletter and veteran pandas contributor Marco Gorelli highlights that the pandas 2.0.0 release candidate is out! If you get the chance do try it out and report any bugs before the final 2.0.0 release in a couple of weeks: to install $pip install pandas==2.0.0rc0
Jona Shehu draws our attention to what looks like an excellent new podcast series from the SAIS Project (a cross-disciplinary collaboration between King’s College London and Imperial College London, and non-academic partners like Microsoft) on the security of AI assistants: “Always Listening: Can I trust my AI Assistant?“. The first episode is already out. In addition, they have also launched a blog series to disseminate SAIS research findings (see blog 1 and blog 2. )
Harin Sellahewa is pleased to highlight success stories from apprentices who completed the Level 7 Digital and Technology Solutions Specialist (Data Analytics Specialist) degree apprenticeship from Buckingham – see Maddie Fang’s story here. The Level 7 DTSS apprenticeship is an excellent route for individuals to upskill or reskill, and for organisations to develop their capabilities in data science
Sian Fortt at the The Alan Turing Institute highlights the upcoming AI UK 2023 conference on the 21-22 March – “The UK’s national showcase of data science and artificial intelligence (AI)”- tickets here
Jobs!
The Job market is a bit quiet – let us know if you have any openings you’d like to advertise
This looks exciting – C3.ai are hiring Data Scientists and Senior Data Scientists to start ASAP in the London office- check here for more details
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
January reminded us (in the UK at least) of the joys of a ‘big coat’ with 2023 definitely off to a cold start… No great change to the depressing headlines though so hopefully time for a bit of distraction with a wrap up of data science developments in the last month. Don’t miss out on more ChatGPT fun and games in the middle section!
Following is the February edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are still actively planning our activities for the year, and are currently working with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
In addition, the RSS is hosting a corporate workshop to discuss how the RSS can help engage employers of data scientists: “We are looking for leaders in the data/stats profession working in the private sector to contribute thoughts and ideas to help shape the RSS corporate and membership offering that will meet the needs of data strategies across private sector organisations.”- Wednesday 08 February 2023, 9.00AM – 12.00PM in the Shard (book here for free)
This year’s RSS International Conference will take place in the lovely North Yorkshire spa town of Harrogate from 4-7 September. As usual Data Science is one of the topic streams on the conference programme, and there is currently an opportunity to submit your work for presentation. There are options available for 20-minute talks, 5-minute rapid-fire talks and for poster presentations – for full details visit the conference website. The deadline for talk submissions is 5 April. Registration has also opened with an extra discount for RSS Fellows available until 17 February.
The AI Standards Hub, led by Florian Ostmann, is organising a webinar on 17th February (sign up here) on harmonising standards to support the implementation of the EU AI Act. The event will feature Sebastian Hallensleben, the chair of the CEN-CENELC committee tasked with developing these standards.
Giles Pavey, Global Director of Data Science at Unilever, was featured in Tom Davenport’s new book “All in on AI” talking about how companies can implement AI Assurance in a proportionate manner.
One of the key arguments is that the generative models have been trained on copyrighted materials without permission – in fact Getty Images has now sued Stable Diffusion as discussed here by the PinsentMasons team (if you are worried your materials might have been included in the training data, you can check here)
And it’s not just images, as author Séamas O’Reilly points out
"I had hoped the entire book would be written in a flurry of nonsensical synonyms, with every word changed to an increasingly absurd alternative, like when song lyrics get spun back and forth between multiple languages on Google Translate.
In fact, the AI has presumably worked out exactly how little it needs to do to get out of trouble, and I get to the end of the book mostly bemused and, weirdest of all, disappointed by its lack of effort."
Stepping back, it’s sometimes useful to remember that we don’t need AI to highlight bias in action…
"Changing my feminine first name to a masculine nickname on my resume gave me way more responses per application.
Just a heads up to any other women that this could also work for. My name isn’t typically associated with a more masculine sounding nickname so I had to get a bit creative. Happy to help anyone who needs it brainstorm a nickname.
I’m so tired."
At AWS, we think responsible AI encompasses a number of core dimensions including:
Fairness and bias– How a system impacts different subpopulations of users (e.g., by gender, ethnicity)
Explainability– Mechanisms to understand and evaluate the outputs of an AI system
Privacy and Security– Data protected from theft and exposure
Robustness– Mechanisms to ensure an AI system operates reliably
Governance– Processes to define, implement and enforce responsible AI practices within an organization
Transparency– Communicating information about an AI system so stakeholders can make informed choices about their use of the system
Developments in Data Science Research…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
Some promising research in combating Generative AI’s fluent falsehoods and identifying AI based content:
First of all, we can attempt to build better models- DeepMind’s ‘Sparrow’ (actually published – but not released – prior to ChatGPT) is supposedly better than CharGPT at “communicating in a way that’s more helpful, correct, and harmless” as more learning from human feedback is incorporated.
Then we have watermarking: “embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens” making it easy to identify human from machine…
But who needs watermarks when you have DetectGPT which can apparently identify AI generated text without any training data, based purely on the “log probabilities computed by the model of interest”
Clearly Generative AI is very much a hot topic, so lots of research probing how to make the models better or trying different approaches:
Who needs diffusion models (the piece of DALLE etc that generates the image) when you have StyleGAN-T which apparently matches existing models but with increased speed. Of course why choose either or when you could have both- using Diffusion models to train GANs…(GANs – Generative adversarial networks – are fun and worth checking out)
But now Google has released MUSE (text to image model) which uses masked transformers and is apparantly faster still…
And not to be outdone, Meta/Facebook has released MAV3D which generates 3d videos from text!
"The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos"
Also Generative AI keeps expanding from text and images…
Google released MusicLM which, you guessed it, generated music from text… I know, you’ve always wanted “a calming violin melody backed by a distorted guitar riff”. And apparently, large language models are natural drummers – “fine-tuning large language models pre-trained on a massive text corpus on only hundreds of MIDI files of drum performances”
One of the key current research areas for generative models, is how best to include information external to the model (other facts or corpuses, more human feedback etc)
OpenAI have a new model which is focused on following more complex instructions (InstructGPT)
While “Demonstrate-Search-Predict” seems to be promising in terms of incorporating additional external information (Retrieval-augmented in-context learning); see also REACT for images (“a framework to acquire the relevant web knowledge to build customized visual models for target domains”)
We can now adapt the output images using additional text prompts with InstructPix2Pix “given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image”
GLIGEN allows different “grounding” information to be included in the prompt to better hone the output (e.g. caption and bounding boxes along with the text prompt)
"PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained to reconstruct the pixels of masked patches instead of predicting a distribution over tokens. "
Generative AI … oh my!
Still such a hot topic it feels in need of it’s own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT…
"In terms of underlying techniques, ChatGPT is not particularly innovative ... Why hasn't the public seen programs like ChatGPT from Meta or from Google? The answer is, Google and Meta both have a lot to lose by putting out systems that make stuff up," says Meta's chief AI scientist, Yann LeCun."
There has been a fair amount of discussion on the use of tools like ChatGPT in education and elsewhere:
Stack Overflow has banned it, as has the prestigious ICML (International Conference on Machine Learning)- “Papers that include text generated from a large-scale language model (LLM) such as ChatGPT are prohibited unless the produced text is presented as a part of the paper’s experimental analysis.“
And clearly detecting when text has been generated from ChatGPT-like models will likely be very important going forward (as discussed in the Research section above) with some tools already available (e.g. GPTZero)
As mentioned above, one area when ChatGPT like tools are causing considerable interest is in coding:
Nice read on reverse engineering of GitHub Copilot 🪄. Copilot has dramatically accelerated my coding, it's hard to imagine going back to "manual coding". Still learning to use it but it already writes ~80% of my code, ~80% accuracy. I don't even really code, I prompt. & edit. https://t.co/kvQTOex9Qj
"The Socratic Method, named after the Greek philosopher Socrates, is anchored on dialogue between teacher and students, fueled by a continuous probing stream of questions. The method is designed to explore the underlying perspectives that inform a student’s perspective and natural interests. ... Imagine history “taught” through a chat interface that allows students to interview historical figures. Imagine a philosophy major dueling with past philosophers - or even a group of philosophers with opposing viewpoints."
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
Always good to see real world examples using cutting edge techniques –
Perplexity.ai is attempting to combined generative results with search and source material to solve the trustfulness issue… with what looks to be good results
"However, as with so many AI applications lately, this development raises questions about what might happen to human narrators working in the business—as well as concerns over who benefits most. If AI narrators become something readers commonly accept and enjoy, it could increase the leverage Apple and other tech companies have over publishers and authors who want as many people as possible to see or hear their work."
It feels like large language models specifically augmented with reputable medical domain information could be incredibly useful – and it looks like DeepMind are moving in that direction with MedPALM
Excited to share Med-PaLM, a large language model aligned to the medical domain to generate safe and helpful answers.
Finally, what looks like excellent work at LinkedIn on observational causal inference “a collection of methods to estimate treatment effects when the treatment is observed rather than randomly assigned” – well worth a read both in terms of how they do and how they have scaled it with their ocelot platform.
How does that work?
Tutorials and deep dives on different approaches and techniques
First of all more pointers on our favourite multi-purpose mechanism… transformers
"Large transformer models are mainstream nowadays, creating SoTA results for a variety of tasks. They are powerful but very expensive to train and use. The extremely high inference cost, in both time and memory, is a big bottleneck for adopting a powerful transformer for solving real-world tasks at scale."
"A few weeks ago, ChatGPT emerged and launched the public discourse into a set of obscure acronyms: RLHF, SFT, IFT, CoT, and more, all attributed to the success of ChatGPT. What are these obscure acronyms and why are they so important? We surveyed all the important papers on these topics to categorize these works, summarize takeaways from what has been done, and share what remains to be shown."
Given the recent improvements in chat-bots, there is a fair bit of interest in applying the state of the art techniques to a custom domain (“how do I apply ChatGPT to my customer service?”)…
"Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you are able to combine them with other sources of computation or knowledge.
This library is aimed at assisting in the development of those types of applications"
Getting a bit more maths and statsy…
Superposition, Memorization, and Double Descent – “This suggests a naive mechanistic theory of overfitting and memorization: memorization and overfitting occur when models operate on “data point features” instead of “generalizing features“
"Shapley values - and their popular extension, SHAP - are machine learning explainability techniques that are easy to use and interpret. However, trying to make sense of their theory can be intimidating. In this article, we will explore how Shapley values work - not using cryptic formulae, but by way of code and simplified explanations."
Finally, if you really want to learn about large language models learn from the best…
Annotating and editing training data, weeding out and correcting bad examples is always tricky to manage – cleanlab looks like a promising open source solution (also prodi.gy)
“Correlation doesn’t imply causation, but it does waggle its eyebrows suggestively and gesture furtively while mouthing ‘look over there’” – Randall Munroe
Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink! …
“Two paradigms have always existed in computer science: one for building and one for exploring. For a long time, there was no need to put a name to them. Then came Beau Shiel.
Shiel was a manager working on Xerox’s AI Systems, and he was running into a problem. He was using tools and methodologies that relied on a linear roadmap, one where each step led toward an expected outcome. But Shiel didn’t know what the outcome was. He didn’t even know what the steps were. Like many data teams today, Shiel wasn’t building. He was exploring.
In 1983, he wrote a paper called “Power Tools for Programmers” and described his work in a new way: exploratory programming.”
“We want to build more capable machines that partner with people to accomplish a huge variety of tasks. All kinds of tasks. Complex, information-seeking tasks. Creative tasks, like creating music, drawing new pictures, or creating videos. Analysis and synthesis tasks, like crafting new documents or emails from a few sentences of guidance, or partnering with people to jointly write software together. We want to solve complex mathematical or scientific problems. Transform modalities, or translate the world’s information into any language. Diagnose complex diseases, or understand the physical world. Accomplish complex, multi-step actions in both the virtual software world and the physical world of robotics."
"AI is transforming the digital world. Machines can now interpret complex images and human language. They can also generate beautiful images and language—effectively propelling us into a world of Endless Media. While this will forever change our digital lives, the physical world hasn’t yet been impacted in the same way. One major exception has been biology. Here, I’ll make the following claim:
Biology is the most powerful way to transform the physical world using AI."
"One of the main ways computers are changing the textual humanities is by mediating new connections to social science. The statistical models that help sociologists understand social stratification and social change haven’t in the past contributed much to the humanities, because it’s been difficult to connect quantitative models to the richer, looser sort of evidence provided by written documents. But that barrier is dissolving"
"It's like a dark forest that seems eerily devoid of human life – all the living creatures are hidden beneath the ground or up in trees. If they reveal themselves, they risk being attacked by automated predators.
Humans who want to engage in informal, unoptimised, personal interactions have to hide in closed spaces like invite-only Slack channels, Discord groups, email newsletters, small-scale blogs, and digital gardens. Or make themselves illegible and algorithmically incoherent in public venues."
Now, if obtaining the ability of perfect language modeling entails intelligence ("AI-complete"), why did I maintain that building the largest possible language model won't "solve everything"? and was I wrong? ...
Was I wrong? sort of. I was definitely surprised by the abilities demonstrated by large language models. There turned out to be a phase shift somewhere between 60B parameters and 175B parameters, that made language models super impressive. They do a lot more than what I thought a language model trained on text and based on RNNs/LSTMs/Transformers could ever do. They certainly do all the things I had in mind when I cockily said they will "not solve everything".
"Large language models (LLMs) explicitly learn massive statistical correlations among tokens. But do they implicitly learn to form abstract concepts and rules that allow them to make analogies?"
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimates 1 in 70 people in England have Covid (a positive move from last month’s 1 in 45) … but till a far cry from the 1 in 1000 we had in the summer of 2021.
Updates from Members and Contributors
Alison Bailey at the ONS Data Science Campus draws our attention to the UNECE starter guide to using synthetic data for those working in official statistics. The guide provides the reader with info on synthetic data concepts and methods, as well as tools, tips, and practical advice on their implementation within a statistical office, as well as entry points into the academic literature.
Fresh from the success of their ESSnet Web Intelligence Network webinars, the ONS Data Science campus have another excellent webinar coming up:
23 Feb’23 – Methods of Processing and Analysing of Web-Scraped Tourism Data. This webinar will discuss the issues of data sources available in tourism statistics. We will present how to search for new data sources and how to analyse them. We will review and apply methods for merging and combining the web scraped data with other sources, using various programming environments. Sign up here
Jobs!
The Job market is a bit quiet – let us know if you have any openings you’d like to advertise
This looks like a really interesting opportunity – Data Scientist at OurWorldInData – see here for details. OurWorldInData is a nonprofit with close ties to the University of Oxford, with a mission to make the world’s data and research easier to access and understand, so that we can collectively make progress against some of the big problems facing humanity, such as climate change, poverty, and much more
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
2023- Happy New Year!…Hope you had a fun and festive holiday season or at least drank and ate enough to take your mind off the strikes, energy prices, cost of living crisis, war in Ukraine and all the other depressing headlines… Perhaps time for something a little different, with a wrap up of data science developments in the last month. Don’t miss out on the ChatGPT fun and games in the middle section!
Following is the January edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are clearly a bit biased… but the section had a fantastic year in 2022! Highlights included 4 engaging and thought provoking meetups, a RSS conference lecture, direct input into the UK AI policy strategy and roadmap, ongoing advocacy and support for Open Source, significant input and support for the new Advanced Data Science Professional Certification, support for the launch of the RSS “real World data Science” platform, 11 newsletters and 2 socials! We are looking to improve on that list in 2023 and are busy planning activities under our new Chair, Janet Bastiman (Chief Data Scientist, Napier AI).
The RSS is now accepting applications for the Advanced Data Science Professional certification, awarded as part of our work with the Alliance for Data Science Professionals – more details here.
"We’re hearing stories of police turning up on people’s doorsteps asking them their whereabouts during the protests, and this appears to be based on the evidence gathered through mass surveillance,” said Alkan Akad, a China researcher at Amnesty International. “China’s ‘Big Brother’ technology is never switched off, and the government hopes it will now show its effectiveness in snuffing out unrest,” he added."
The 10 guiding principles identify areas where the International Medical Device Regulators Forum (IMDRF), international standards organizations, and other collaborative bodies could work to advance GMLP. Areas of collaboration include research, creating educational tools and resources, international harmonization, and consensus standards, which may help inform regulatory policies and regulatory guidelines.
We envision these guiding principles may be used to:
- Adopt good practices that have been proven in other sectors
- Tailor practices from other sectors so they are applicable to medical technology and the health care sector
- Create new practices specific for medical technology and the health care sector
While new techniques continue to evolve in the Medical AI sector: “Predicting sex from retinal fundus photographs using automated deep learning“. Research like this highlights the importance of widely followed best practices regarding how information obtained through AI (in this case the sex of the patient) can be used.
It’s hard to explain the feeling when a Cruise vehicle pulls up to pick you up with no one in the driver’s seat.
There’s a bit of apprehension, a bit of wonder, a bit of: “Is this actually happening?”
And in my case, there was a bit of a walk as the car came to a stop across the street from our chosen pickup point in Pacific Heights. The roughly half-hour drive to the Outer Richmond (paid for by Cruise) made me feel like I was in the hands of an incredibly cautious student driver, complete with nervous, premature stops, a 25 mph speed limit and no right turns on red lights.
We’ll have lots more Generative AI fun and games later in the newsletter, but the ethical questions around “stealing styles” continue, and a new viral AI avatar app called Lensa has caused a good deal of controversy by highlighting the bias inherent in the underlying image training set used in the app (coverage from Wired and an excellent piece in MIT Technology Review)
I have Asian heritage, and that seems to be the only thing the AI model picked up on from my selfies. I got images of generic Asian women clearly modeled on anime or video-game characters. Or most likely porn, considering the sizable chunk of my avatars that were nude or showed a lot of skin. A couple of my avatars appeared to be crying. My white female colleague got significantly fewer sexualized images, with only a couple of nudes and hints of cleavage. Another colleague with Chinese heritage got results similar to mine: reams and reams of pornified avatars.
These same systems are also likely to reproduce discriminatory and abusive behaviors represented in their training data, especially when the data encodes human behaviors. The technology then has the potential to make these issues significantly worse
As a result, all of this money has shaped the field of AI and its priorities in ways that harm people in marginalized groups while purporting to work on “beneficial artificial general intelligence” that will bring techno utopia for humanity. This is yet another example of how our technological future is not a linear march toward progress but one that is determined by those who have the money and influence to control it.
Developments in Data Science Research…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
Why do dreams – which are always so interesting – just disappear? Francis Crick (who played an important role in deciphering the structure of DNA) and Graeme Mitchison had this idea that we dream in order to get rid of things that we tend to believe, but shouldn’t. This explains why you don’t remember dreams.
Forward Forward builds on this idea of contrastive learning and processing real and negative data. The trick of Forward Forward, is you propagate activity forwards with real data and get one gradient. And then when you’re asleep, propagate activity forward again, starting from negative data with artificial data to get another gradient. Together, those two gradients accurately guide the weights in the neural network towards a better model of the world that produced the input data.
And now we have the ‘Masked ViT’ – a novel way of pre-training vision transformers using a self-supervised learning approach that masks out portions of the the training images – resulting in faster training and better predictions
And not content with conquering vision, transformers move into robotics (RT-1 Robotics transformer for real world control at scale)!
The new generative AI models rely on connecting visual and textual representations together (e.g. CLIP inside DALLE), often using a labelled training set of examples. But are there biases in these labelled training sets?
"We conduct an in-depth exploration of the CLIP model and show that its visual representation is often strongly biased towards solving some tasks more than others. Moreover, which task the representation will be biased towards is unpredictable, with little consistency across images"
This is pretty amazing… Given the potential biases in the multi-modal training sets (see last item) is it possible to use pixels alone– ie train both image and language models using just the pixels of the images or the text rendered as images?
Our model is trained with contrastive loss alone, so we call it CLIP-Pixels Only (CLIPPO). CLIPPO uses a single encoder that processes both regular images and text rendered as images. CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP, with half the number of parameters and no text-specific tower or embedding. When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work.
"The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.."
Meanwhile Facebook/Meta have released Data2vec 2.0 which unifies self-supervised learning across vision, speech and text
DeepMind have released DeepNash, an AI system that learned to play Stratego from scratch to a human expert level by playing against itself. This is impressive as Stratego is a game of imperfect information (unlike Chess and Go): players cannot directly observe the identities of their opponent’s pieces.
"Brains contain networks of interconnected neurons, so knowing the network architecture is essential for understanding brain function. We therefore mapped the synaptic-resolution connectome of an insect brain (Drosophila larva) with rich behavior, including learning, value-computation, and action-selection, comprising 3,013 neurons and 544,000 synapses ... Some structural features, including multilayer shortcuts and nested recurrent loops, resembled powerful machine learning architectures"
Stable-Dal-Gen oh my...and ChatGPT!
We’ll pause on text to image for a moment to focus on the newest and coolest kid in town- ChatGPT from OpenAI. Even though in reality it is not much more sophisticated than the underlying language models which have been around for sometime, the interface seems to have made it more accessible, and the use cases more obvious – and so has generated a lot (!) of comment.
First of all, what is it? Well, its a chat bot: type in something (anything from “What is the capital of France” to “Write a 1000 word essay on the origins of the French Revolution from the perspective of an 18th Century English nobleman” ), and you get a response. See OpenAI’s release statement here, and play around with it here (sign up for a free login). Some local implementations here and here. And some “awesome prompts” to tryout here.
“For more than 20 years, the Google search engine has served as the world’s primary gateway to the internet. But with a new kind of chat bot technology poised to reinvent or even replace traditional search engines, Google could face the first serious threat to its main search business. One Google executive described the efforts as make or break for Google’s future.”
ChatGPT is sometimes amazing, and sometimes hilariously wrong. Here, it confidently explains to me why an abacus is faster than a GPU. 😃 pic.twitter.com/vpJZTStDnD
Lots of practical examples making a difference in the real world this month!
OpenAI has released something in addition to ChatGPT! – Point-E an AI that generates 3-D models. It uses a novel approach- it generates point clouds, or discrete sets of data points in space that represent a 3D shape (paper)
Implementations of a two different Transformer based time series approaches (PatchTST and GBT) … and a paper with code comparing Deep Learning and statistical approaches to time series
Lots going on in the Healthcare/Medical space
This looks promising – PubMed GPT, a domain specific large language model for biomedical text, together with MultiMedQA for benchmarking LLM’s clinical knowledge
Stanford researchers have generated imitation lung X-rays with diagnosable pathologies from a custom version of Stable Diffusion
"These protein generators can be directed to produce designs for proteins with specific properties, such as shape or size or function. In effect, this makes it possible to come up with new proteins to do particular jobs on demand. Researchers hope that this will eventually lead to the development of new and more effective drugs. “We can discover in minutes what took evolution millions of years,” says Gevorg Grigoryan, CTO of Generate Biomedicines.
“What is notable about this work is the generation of proteins according to desired constraints,” says Ava Amini, a biophysicist at Microsoft Research in Cambridge, Massachusetts."
How does that work?
Tutorials and deep dives on different approaches and techniques
"The more adept LLMs become at mimicking human language, the more vulnerable we become to anthropomorphism, to seeing the systems in which they are embedded as more human-like than they really are. This trend is amplified by the natural tendency to use philosophically loaded terms, such as "knows", "believes", and "thinks", when describing these systems. To mitigate this trend, this paper advocates the practice of repeatedly stepping back to remind ourselves of how LLMs, and the systems of which they form a part, actually work."
"If you find that your F1 / recall / accuracy score isn’t getting better with more labels, it’s critical that you understand why this is happening. You need to be able to compare label distributions and imbalance between dataset versions. You need to compare top error contributors, check for new negative noise introduced, among many other things. Today this process is extremely cumbersome even when possible, involving lots of copying, complicated syntax, and configuration files that need to be managed separately from the data itself."
"While there are a growing number of blog posts and tutorials on the challenges of training large ML models, there are considerably fewer covering the details and approaches for training many ML models. We’ve seen a huge variety of approaches ranging from services like AWS Batch, SageMaker, and Vertex AI to homegrown solutions built around open source tools like Celery or Redis.
Ray removes a lot of the performance overhead of handling these challenging use cases, and as a result users often report significant performance gains when switching to Ray. Here we’ll go into the next level of detail about how that works."
“Consider the number of examples necessary to learn a new task, known as sample complexity. It takes a huge amount of gameplay to train a deep learning model to play a new video game, while a human can learn this very quickly. Related issues fall under the rubric of reasoning. A computer needs to consider numerous possibilities to plan an efficient route from here to there, while a human doesn’t.”
“And artificial intelligence has always flirted with biology — indeed, the field takes inspiration from the human brain as perhaps the ultimate computer. While understanding how the brain works and creating brainlike AI has long seemed like a pipe dream to computer scientists and neuroscientists, a new type of neural network known as a transformer seems to process information similarly to brains"
"A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). "
"Programming will be obsolete. I believe the conventional idea of "writing a program" is headed for extinction, and indeed, for all but very specialized applications, most software, as we know it, will be replaced by AI systems that are trained rather than programmed. In situations where one needs a "simple" program (after all, not everything should require a model of hundreds of billions of parameters running on a cluster of GPUs), those programs will, themselves, be generated by an AI rather than coded by hand."
"One interpretation of this fact is that current language models are still not “good enough” – we haven’t yet figured out how to train models with enough parameters, on enough data, at a large enough scale. But another interpretation is that, at some level, language models are not quite solving the problem that me might want. This latter interpretation is often brought forward as a fundamental limitation of language models, but I will argue that in fact it suggests a different way of using language models that may turn out to be far more powerful than some might suspect."
The way we think about AI is shaped by works of science-fiction. In the big picture, fiction provides the conceptual building blocks we use to make sense of the long-term significance of “thinking machines” for our civilization and even our species. Zooming in, fiction provides the familiar narrative frame leveraged by the media coverage of new AI-powered product releases.
"We found that across the board, modern AI models do not appear to have a robust understanding of the physical world. They were not able to consistently discern physically plausible scenarios from implausible ones. In fact, some models frequently found the implausible event to be less surprising: meaning if a person dropped a pen, the model found it less surprising for it to float than for it to fall. This also means that, at their current level of development, the models that could eventually drive our cars may lack a core physical understanding that they cannot drive through a brick wall."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
“There is a cat that wanders around my neighbourhood. I wanted to build something that would notify me whenever it came to my backyard.” Cats, Pi, and Machine Learning
The latest results from the ONS tracking study estimate 1 in 45 people in England have Covid (another increase from last month’s 1 in 60) … but till a far cry from the 1 in 1000 we had in the summer of 2021.
Fresh from the success of their ESSnet Web Intelligence Network webinars, the ONS Data Science campus have another excellent set of webinars coming up:
24 Jan’23 – Enhancing the Quality of Statistical Business Registers with Scraped Data. This webinar will aim to inspire and equip participants keen to use web-scraped information to enhance the quality of the Statistical Business Registers. Sign up here
23 Feb’23 – Methods of Processing and Analysing of Web-Scraped Tourism Data. This webinar will discuss the issues of data sources available in tourism statistics. We will present how to search for new data sources and how to analyse them. We will review and apply methods for merging and combining the web scraped data with other sources, using various programming environments. Sign up here
Jobs!
The Job market is a bit quiet – let us know if you have any openings you’d like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Don’t miss out on our latest meetup – “Why AI in healthcare isn’t working”
Please join us for a panel discussion on the topic of “Why AI in healthcare isn’t working”. In this session we will be discussing with experts in the field on the current state of AI in healthcare. We will cover the successes, the failures and what needs to happen to get more of the former than the latter.
We will be joined by the ex President of the European Society for AI in Medicine, Professor Jeremy Wyatt and Dr Louisa Nolan, Head of Public Health Data Science, Public Health Wales
Looking forward to seeing you there
Thursday 15 December 2022, 7.00PM – 8.30PM – Online
December already… Happy Holidays to everyone! It certainly feels like winter is here judging by the lack of sunlight. But a December like no other, as we have a World Cup to watch – although half empty, beer-less, air-conditioned stadiums in repressive Qatar does not sit well …Perhaps time for a breather, with a wrap up of data science developments in the last month.
Following is the December edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
The RSS is now accepting applications for the Advanced Data Science Professional certification, awarded as part of our work with the Alliance for Data Science Professionals – more details here.
We are very excited to announce Real World Data Science, a new data science content platform from the Royal Statistical Society. It is being built for data science students, practitioners, leaders and educators as a space to share, learn about and be inspired by real-world uses of data science. Case studies of data science applications will be a core feature of the site, as will “explainers” of the ideas, tools, and methods that make data science projects possible. The site will also host exercises and other material to support the training and development of data science skills. Real World Data Science is online at realworlddatascience.net (and on Twitter @rwdatasci). The project team has recently published a call for contributions, and those interested in contributing are invited to contact the editor, Brian Tarran.
Martin has also compiled a handy list of mastodon handles as the data science and machine learning community migrates away from twitter…
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
How do we assess large language models?
Facebook released Galactica – ‘a large language model for science’. On the face of it, this was a very exciting proposition, using the architecture and approach of the likes of GPT-3 but trained on a large scientific corpus of papers, reference material, knowledge bases and many other sources.
Sadly, it quickly became apparent that the output of the model could not be trusted- often it got a lot right, but it was impossible to tell right from wrong
I asked #Galactica about some things I know about and I'm troubled. In all cases, it was wrong or biased but sounded right and authoritative. I think it's dangerous. Here are a few of my experiments and my analysis of my concerns. (1/9)
"Maybe you don’t mind if GitHub Copilot used your open-source code without asking.
But how will you feel if Copilot erases your open-source community?"
For a few thousand dollars a year, Social Sentinel offered schools across the country sophisticated technology to scan social media posts from students at risk of harming themselves or others. Used correctly, the tool could help save lives, the company said.
For some colleges that bought the service, it also served a different purpose — allowing campus police to surveil student protests.
First of all, the dreaded job losses driven by increased automation and AI implementation does not seem to have happened so far at least, according to the BLS.
While Facebook has released their competitor to AlphaFold using a large language model approach, positive news in the open source community with the released of OpenFold, and open source version of DeepMind’s impressive AlphaFold
"AlphaFold2 revolutionized structural biology with the ability to predict protein structures with exceptionally high accuracy. Its implementation, however, lacks the code and data required to train new models. These are necessary to (i) tackle new tasks, like protein-ligand complex structure prediction, (ii) investigate the process by which the model learns, which remains poorly understood, and (iii) assess the model's generalization capacity to unseen regions of fold space. Here we report OpenFold, a fast, memory-efficient, and trainable implementation of AlphaFold2, and OpenProteinSet, the largest public database of protein multiple sequence alignments. ”
Developments in Data Science Research…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
A good place to start – the ‘Outstanding Papers’ from NeurIPS 2022. A wide variety of topics covered including diffusion and other generative models and efficient scaling.
“Hallucinations” in Natural Language Generation – “However, it is also apparent that deep learning based generation is prone to hallucinate unintended text, which degrades the system performance and fails to meet user expectations in many real-world scenarios”
"In Emergent abilities of large language models, we defined an emergent ability as an ability that is “not present in small models but is present in large models.” Is emergence a rare phenomena, or are many tasks actually emergent?
It turns out that there are more than 100 examples of emergent abilities that already been empirically discovered by scaling language models such as GPT-3, Chinchilla, and PaLM. To facilitate further research on emergence, I have compiled a list of emergent abilities in this post. "
In this work, we pursue an ambitious goal of translating between molecules and language by proposing two new tasks: molecule captioning and text-guided de novo molecule generation. In molecule captioning, we take a molecule (e.g., as a SMILES string) and generate a caption that describes it. In text-guided molecule generation, the task is to create a molecule that matches a given natural language description
We analyze the knowledge acquired by AlphaZero, a neural network engine that learns chess solely by playing against itself yet becomes capable of outperforming human chess players. Although the system trains without access to human games or guidance, it appears to learn concepts analogous to those used by human chess players. We provide two lines of evidence. Linear probes applied to AlphaZero’s internal state enable us to quantify when and where such concepts are represented in the network. We also describe a behavioral analysis of opening play, including qualitative commentary by a former world chess champion.
A novel new approach to zero shot transfer learning – CLOOB – with results that seem to outperform CLIP, one of the the key approaches used in current state of the art generative models like Stable Diffusion that connects text to images.
"Results show that tree-based models remain state-of-the-art on medium-sized data (10K samples) even without accounting for their superior speed. To understand this gap, we conduct an empirical investigation into the differing inductive biases of tree-based models and neural networks. This leads to a series of challenges which should guide researchers aiming to build tabular-specific neural network: 1) be robust to uninformative features, 2) preserve the orientation of the data, and 3) be able to easily learn irregular functions."
Stable-Dal-Gen oh my…
Still lots of discussion about the new breed of text-to-image models (type in a text prompt/description and an -often amazing- image is generated) with three main models available right now: DALLE2 from OpenAI, Imagen from Google and the open source Stable-Diffusion from stability.ai.
An interesting bi-product of the embedding that happens in Neural Networks is the potential for file compression
The team at Netflix discuss how they have improved video quality by using their own video encoding optimisation based on deep learning architectures
Meanwhile the Facebook/Meta AI team have released a new audio codec with a 10x improvement in compression compared to mp3 which could be very useful in low bandwidth situations
More interesting and practical time series work including optimisation based on forecast models (as an aside, NeuralForecast looks a useful package for experimenting with NN based time series models):
Very impressive – CICERO: An AI agent that negotiates, persuades, and cooperates with people.
"Today, we’re announcing a breakthrough toward building AI that has mastered these skills. We’ve built an agent – CICERO – that is the first AI to achieve human-level performance in the popular strategy game Diplomacy*"
"Diplomacy has been viewed for decades as a near-impossible grand challenge in AI because it requires players to master the art of understanding other people’s motivations and perspectives; make complex plans and adjust strategies; and then use natural language to reach agreements with other people, convince them to form partnerships and alliances, and more. CICERO is so effective at using natural language to negotiate with people in Diplomacy that they often favored working with CICERO over other human participants."
Finally, great summary post from Jeff Dean at Google highlighting how AI is driving worldwide progress in 3 significant areas: Supporting thousands of languages; Empowering creators and artists; Addressing climate change and health challenges – well worth a read
How does that work?
Tutorials and deep dives on different approaches and techniques
"Contrastive learning is a powerful class of self-supervised visual representation learning methods that learn feature extractors by (1) minimizing the distance between the representations of positive pairs, or samples that are similar in some sense, and (2) maximizing the distance between representations of negative pairs, or samples that are different in some sense. Contrastive learning can be applied to unlabeled images by having positive pairs contain augmentations of the same image and negative pairs contain augmentations of different images."
Excellent python library, pythae, for comparing different AutoEncoders – definitely worth playing around with if you get the time
"Enterprises are full of documents containing knowledge that isn't accessible by digital workflows. These documents can vary from letters, invoices, forms, reports, to receipts. With the improvements in text, vision, and multimodal AI, it's now possible to unlock that information. This post shows you how your teams can use open-source models to build custom solutions for free!"
Practical tips
How to drive analytics and ML into production
Useful insight from Shopify on reducing BigQuery costs- how they fixed their $1m query. In a similar vein this is a useful study comparing two open source table formats: Delta lake and Apache Iceberg (spoiler alert… Delta Lake is faster)
"By far, the most expensive, complex, and performant method is a fully realtime ML pipeline; the model runs in realtime, the features run in realtime, and the model is trained online, so it is constantly learning. Because the time, money, and resources required by a fully realtime system are so extensive, this method is infrequently utilized, even by FAANG-type companies, but we highlight it here because it is also incredible what this type of realtime implementation is capable of."
This is sad to see – a data scientist leaving the field. Lots in this post that I’m sure will resonate with many- highlights the importance of good technical senior management
"The reason managers pursued these insane ideas is partly because they are hired despite not having any subject matter expertise in business or the company’s operations, and partly because VC firms had the strange idea that ballooning costs well in excess of revenue was “growth” and therefore good in all cases; the business equivalent of the Flat Earth Society."
“A central goal of recommender systems is to select items according to the “preferences” of their users. “Preferences” is a complicated word that has been used across many disciplines to mean, roughly, “what people want.” In practice, most recommenders instead optimize for engagement. This has been justified by the assumption that people always choose what they want, an idea from 20th-century economics called revealed preference. However, this approach to preferences can lead to a variety of unwanted outcomes including clickbait, addiction, or algorithmic manipulation.
Doing better requires both a change in thinking and a change in approach. We’ll propose a more realistic definition of preferences, taking into account a century of interdisciplinary study, and two concrete ways to build better recommender systems: asking people what they want instead of just watching what they do, and using models that separate motives, behaviors, and outcomes.”
“For instance, as an occasional computer vision researcher, my goal is sometimes to prove that my new image classification model works well. I accomplish this by measuring its accuracy, after asking it to label images (is this image a cat or a dog or a frog or a truck or a ...) from a standardized test dataset of images. I'm not allowed to train my model on the test dataset though (that would be cheating), so I instead train the model on a proxy dataset, called the training dataset. I also can't directly target prediction accuracy during training1, so I instead target a proxy objective which is only related to accuracy. So rather than training my model on the goal I care about — classification accuracy on a test dataset — I instead train it using a proxy objective on a proxy dataset."
"But the best is yet to come. The really exciting applications will be action-driven, where the model acts like an agent choosing actions. And although academics can argue all day about the true definition of AGI, an action-driven LLM is going to look a lot like AGI."
"However, I worry that many startups in this space are focusing on the wrong things early on. Specifically, after having met and looked into numerous companies in this space, it seems that UX and product design is the predominant bottleneck holding back most applied large language model startups, not data or modeling"
"We are rapidly pursuing the industrialization of biotech. Large-scale automation now powers complex bio-foundries. Many synthetic biology companies are hellbent on scaling production volumes of new materials. A major concern is the shortage of bioreactors and fermentation capacity. While these all seem like obvious bottlenecks for the Bioeconomy, what if they aren’t? What if there is another way? Here, I’ll explore a different idea: the biologization of industry."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 60 people in England have Covid (a slight increase from last week’s 1 in 65)- a lot better than last month (1 in 35) … but till a far cry from the 1 in 1000 we had in the summer of 2021.
Mia Hatton from the ONS Data Science campus is looking for feedback from any government and public sector employees who have an interest in data science to help shape the future of the committee- check out the survey here (you can also join the mailing list here).
Fresh from the success of their ESSnet Web Intelligence Network webinars, the ONS Data Science campus have another excellent set of webinars coming up:
24 Jan’23 – Enhancing the Quality of Statistical Business Registers with Scraped Data. This webinar will aim to inspire and equip participants keen to use web-scraped information to enhance the quality of the Statistical Business Registers. Sign up here
23 Feb’23 – Methods of Processing and Analysing of Web-Scraped Tourism Data. This webinar will discuss the issues of data sources available in tourism statistics. We will present how to search for new data sources and how to analyse them. We will review and apply methods for merging and combining the web scraped data with other sources, using various programming environments. Sign up here
Jobs!
The Job market is a bit quiet over the summer- let us know if you have any openings you’d like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Another month, another UK Prime Minister it seems – certainly the rate of political dramas doesn’t seem to be slowing…Perhaps time for a breather, with a wrap up of data science developments in the last month.
Following is the November edition of our Royal Statistical Society Data Science and AI Section newsletter- apologies it’s a little later than normal. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Having successfully convened not 1, but 2 entertaining and insightful data science meetups over the last couple of months (“From Paper to Pitch” and “IP Freely, making algorithms pay – Intellectual property in Data Science and AI“) – huge thanks to Will Browne! – we thought it might be fun to do something a little more relaxed in the run-up to the Holiday Season. So … you are cordially invited to the “Data Science and AI Christmas Mixer” on 1st December at the Artillery Arms, 102 Bunhill Row, London EC1Y 8ND, an entirely informal event to meet like minded data scientists, moan about the world today and probably find out something interesting about a topic you never knew existed! And in addition, we have another meetup planned for December 15th – “Why is AI in healthcare not working” – save the date!
We are very excited to announce Real World Data Science, a new data science content platform from the Royal Statistical Society. It is being built for data science students, practitioners, leaders and educators as a space to share, learn about and be inspired by real-world uses of data science. Case studies of data science applications will be a core feature of the site, as will “explainers” of the ideas, tools, and methods that make data science projects possible. The site will also host exercises and other material to support the training and development of data science skills. Real World Data Science is online at realworlddatascience.net (and on Twitter @rwdatasci). The project team has recently published a call for contributions, and those interested in contributing are invited to contact the editor, Brian Tarran.
Huge congratulations to committee member Florian Ostmann for the successful launch of The AI Standards Hub on 12 October. Part of the National AI Strategy, the Hub’s new online platform and activities are dedicated to knowledge sharing, community building, strategic research, and international engagement around standardisation for AI technologies.
If you missed the AI Standards Hub launch event, you can watch the recording here. The Hub’s initial focus will be on trustworthy AI as a horizontal theme, with deep dives on (i) transparency and explainability, (ii) safety, security and resilience, and (iii) uncertainty quantification. A first webinar and workshop on standards for transparency and explainability will be announced soon – please sign up for the newsletter to receive updates if you are interested.
Janet Bastiman (Chief Data Scientist at Napier AI) recently spoke on “Ethics and Trust in AI” and “Successful AI Implementations” at the Institute of Enterprise Risk Practitioners in Malaysia on 27th October (we are going global!), and has also published an influential paper on “Building Trust and Confidence in AI” in the Journal of AI, Robotics and Workplace Automation
"Normally the most clicked result for our site is 'Canongate', and I tell you what, those people went away satisfied. Canongate was what they were looking for and they found us.
I'm not sure people searching 'sleeping mom porn' were thrilled to get a funny book for parents."
And as the new wave of Generative AI tools gains traction (DALLE, Imagen, Stable Diffusion etc), more moral and ethical questions come to the fore:
And although the models seem to work amazingly well, we really don’t know at a detailed level what issues might be lurking in the way the have been trained or the data included – such as with the strange case of garbled brand names in halloween candy, or when words with multiple meanings are used in the prompt
Regulatory bodies around the world continue to attempt to put some boundaries around what is allowable, while geo-political tensions are on the rise, particularly between the US and China.
"Industry executives say many Chinese industries that rely on artificial intelligence and advanced algorithms power those abilities with American graphic processing units, which will now be restricted. Those include companies working with technologies like autonomous driving and gene sequencing, as well as the artificial intelligence company SenseTime and ByteDance, the Chinese internet company that owns TikTok."
Who doesn’t like a 114 page power point document (!) – yes it’s time for the annual State of AI Report, covering many of the themes we have been discussing (Generative AI, ML driven Science, AI Safety etc)
AI and ML models often fundamentally rely on clear and unambiguous specification of a goal or goals- what is the system trying to optimise. Great paper from Deep Mind talking through the different ways that models can fail to generalise well even when goals are apparently well defined.
"Even though the agent can observe that it is getting negative reward, the agent does not pursue the desired goal to “visit the spheres in the correct order” and instead competently pursues the goal “follow the red agent”
Many of us intrinsically believe that the polarisation we see in politics and cultural topics is driven in some way by our consumption of information on social media. Interesting research shows that this is likely the case, but not because of ‘filter bubbles’ or ‘echo chambers’ – the driver seems to be simple sorting into homogenous groups.
"It is not isolation from opposing views that drives polarization but precisely the fact that digital media bring us to interact outside our local bubble. When individuals interact locally, the outcome is a stable plural patchwork of cross-cutting conflicts. By encouraging nonlocal interaction, digital media drive an alignment of conflicts along partisan lines, thus effacing the counterbalancing effects of local heterogeneity."
Finally, some good news on the open source front – Open Source Reinforcement Learning has a new home: the Farama Foundation
Developments in Data Science Research…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
Again before diving into the arxiv realms, another useful tool for helping understand research papers … ‘explainpaper‘
Lots of interesting work in the robotics field recently – how to build a generalised approach to robotic tasks rather than train each task individually…
Then we have Microsoft Research releasing PACT – “Inspired by large pretrained language models, this work introduces a paradigm for pretraining general purpose representation models that can be used for multiple robotics tasks.”
In addition we have GNM from Berkley Artificial Intelligence Research – ‘A general navigational model to drive any robot’. “In this paper, we study how a general goal-conditioned model for vision-based navigation can be trained on data obtained from many distinct but structurally similar robots, and enable broad generalization across environments and embodiments”
And finally researchers at Carnegie Mellon University have published “Deep Whole Body Control” – “Learning a Unified Policy for Manipulation and Locomotion”
As always lots of work improving everyone’s favourite architecture… transformers
And Wide seems to be better than Deep when it comes to transformers. “We demonstrate that wide single layer Transformer models can compete with or outperform deeper ones in a variety of Natural Language Processing (NLP) tasks when both are trained from scratch”
"Our evaluations on Image classification (ImageNet-1k with and without pre-training on ImageNet-21k), transfer learning and semantic segmentation show that our procedure outperforms by a large margin previous fully supervised training recipes for ViT. It also reveals that the performance of our ViT trained with supervision is comparable to that of more recent architectures. Our results could serve as better baselines for recent self-supervised approaches demonstrated on ViT"
Intriguing look at Weakly Supervised Learning – “We model weak supervision as giving, rather than a unique target, a set of target candidates. We argue that one should look for an “optimistic” function that matches most of the observations. This allows us to derive a principle to disambiguate partial labels”
If you give Large Language Models more context, does it make them better? … yes! “We annotate questions from 40 challenging tasks with answer explanations, and various matched control explanations … We find that explanations can improve performance — even without tuning”
Another entertaining idea – using large language models to generate prompts for input into a large language model!
"In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Experiments on 24 NLP tasks show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 21/24 tasks
Progress on the data side of things…
How much are data augmentations worth? “In this paper, we disentangle several key mechanisms through which data augmentations operate. Establishing an exchange rate between augmented and additional real data, we find that in out-of-distribution testing scenarios, augmentations which yield samples that are diverse, but inconsistent with the data distribution can be even more valuable than additional training data”
How do you keep those massive image data sets clean? Active Image Indexing looks promising to quickly identify duplicates, robust to various transformations.
Back to one of my favourite topics…. can Deep Learning help with tabular data?
I love this idea – just treat tabular data as a natural language string and plug it into an LLM – TabLLM. “Despite its simplicity, we find that this technique outperforms prior deep-learning-based tabular classification methods on several benchmark datasets. In most cases, even zero-shot classification obtains non-trivial performance, illustrating the method’s ability to exploit prior knowledge encoded in large language models”
And of course you can go the other way: use diffusion models to generate tabular data- TabDDPM (repo here). “We extensively evaluate TabDDPM on a wide set of benchmarks and demonstrate its superiority over existing GAN/VAE alternatives, which is consistent with the advantage of diffusion models in other fields.”
Lots of work in time series forecasting with deep learning methods this month. As always, I highly recommend Peter Cotton’s microprediction site for evaluating and comparing time series methods
And what looks to be an impressive library attempting bring all these different methods together – Imbrium
The Google Brain team have released UL2 20B Open Source Unified Language learner which attempts to bridge the gap between autoregressive decoder-only architectures (predict the next word) and encoder-decoder architectures (identify the masked out words).
"During pre-training it uses a novel mixture-of-denoisers that samples from a varied set of such objectives, each with different configurations. We demonstrate that models trained using the UL2 framework perform well in a variety of language domains, including prompt-based few-shot learning and models fine-tuned for down-stream tasks. Additionally, we show that UL2 excels in generation, language understanding, retrieval, long-text understanding and question answering tasks."
A month seems to be a long time in AI research these days. Last month we were raving about text-to-image models (see here for more background) but already we seem to have moved onto video!
‘DreamFusion‘ from Google Research and UC Berkeley generates 3D images from text
Facebook/Meta has jumped into the race with ‘Make-A-Video‘ which generates videos from text (paper here)
Another option is Phenaki, extending the videos to multiple minutes
And Google have enhanced Imagen to create Imagen Video
"We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding."
Finally, DeepMind are at it again… this time releasing AlphaTensor, extending the AlphaZero approach used to crack Go into mathematics
"In our paper, published today in Nature, we introduce AlphaTensor, the first artificial intelligence (AI) system for discovering novel, efficient, and provably correct algorithms for fundamental tasks such as matrix multiplication. This sheds light on a 50-year-old open question in mathematics about finding the fastest way to multiply two matrices.."
Stable-Dal-Gen oh my…
Lots of discussion about the new breed of text-to-image models (type in a text prompt/description and an -often amazing- image is generated) with three main models available right now: DALLE2 from OpenAI, Imagen from Google and the open source Stable-Diffusion from stability.ai.
We are already seeing Generative AI-based tools appearing- RunwayML for the end-to-end image creative process; Descript for video editing;
How about DALL-E-Bot – “DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image”
"This generation process involves 3 different models:
1) A model for converting the text prompt to embeddings. Openai’s CLIP(Contrastive Language-Image Pretraining) model is used for this purpose.
2) A model for compressing the input image to a smaller dimension(this reduces the compute requirement for image generation). A Variational Autoencoder(VAE) model is used for this task.
3) The last model generates the required image according to the prompt and input image. A U-Net model is used for this process."
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
Time series forecasting is hard… and retailers use it all the time to, for instance, decide how to manage supply chain inventory levels. Great to see Amazon talk through the history of their development in this area- well worth a read
Entity matching in data pipelines– potentially very useful and practical – “we implement a (basically) no-code, pure SQL flow that runs entity matching directly in dbt+Snowflake flow. To do it, we abstract away GPT3 API through AWS Lambda, and leverage Snwoflake external functions to make the predictions when dbt is materializing the proper table”
"Create a three-column table with the first date, last date, and job description for each line of text below. Treat each line as a row. Do not skip any rows. If the dates are in the middle or the end of a row, place them in the first two columns and concatenate the text that surround them on the third column. If there are more than two dates and more than one job description in each row, extract the earliest date and the latest date, and concatenate the job descriptions using a semicolon as separator."
How does that work?
Tutorials and deep dives on different approaches and techniques
Extensive repo containing papers and tutorials on diffusion models
I stumbled on this approach – Physics Informed Learning – and found it really interesting. Basically when you have a system with known properties defined by partial differential equations (PDE), you can use a traditional machine learning / deep learning approach but adapt the loss term to include the PDE, which constrains the ML solutions to the known physical properties – elegant
"One of the most appealing advances in Machine Learning over the past 5 years concerns the development of physics informed neural networks (PINNs). In essence, these efforts have amounted into methods which allow to enforce governing physical and chemical laws into the training of neural networks. The approach unveils many advantages especially considering inverse problems or when observational data providing boundary conditions are noisy or gappy."
"Keep a chart simple, letting people choose when they want additional details. Resist the temptation to pack as much data as possible into a chart. Too much data can make a chart visually overwhelming and difficult to use, obscuring the relationships and other information you want to convey"
Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink! …
“Efforts to build a better digital “nose” suggest that our perception of scents reflects both the structure of aromatic molecules and the metabolic processes that make them.”
“We’re looking at whether the AI [programs] could give information that the peer reviewers would find helpful in any way,” Thelwall says. For instance, he adds, AI could perhaps suggest a score that referees could consider during their assessment of papers. Another possibility, Thelwall notes, is AI being used as a tiebreaker if referees disagree strongly on an article — similarly to how REF panels already use citation data."
"It had roots in a broader question, one that the mathematician Carl Friedrich Gauss considered to be among the most important in mathematics: how to distinguish a prime number (a number that is divisible only by 1 and itself) from a composite number. For hundreds of years, mathematicians have sought an efficient way to do so. The problem has also become relevant in the context of modern cryptography, as some of today’s most widely used cryptosystems involve doing arithmetic with enormous primes."
"Now some computational neuroscientists have begun to explore neural networks that have been trained with little or no human-labeled data. These “self-supervised learning” algorithms have proved enormously successful at modeling human language and, more recently, image recognition. In recent work, computational models of the mammalian visual and auditory systems built using self-supervised learning models have shown a closer correspondence to brain function than their supervised-learning counterparts."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 35 people in England have Covid- a lot worse than last month (1 in 65) but at least slightly better than last week… and till a far cry from the 1 in 1000 we had in the summer of 2021.
Prithwis De‘s book is officially out– many congratulations! Check out ‘Towards Net Zero Targets: Usage of Data Science for Long-Term Sustainability Pathways’ here
The ONS Data Science campus have another excellent set of webinars coming up for the for the ESSnet Web Intelligence Network (WIN). The ESSnet WIN project team comprises 18 organisations from 15 European countries and works closely with the Web Intelligence Hub (WIH), a Eurostat project. The next webinar is on 23rd November will cover Architecture, Methodology and Quality of web data- definitely worth checking if you use this type of information in your analyses. Sign up here
Jobs!
The Job market is a bit quiet over the summer- let us know if you have any openings you’d like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Well, September certainly seemed to disappear pretty rapidly (along with the sunshine sadly). And dramatic events keep accumulating, from the sad death of the Queen, together with epic coverage of ‘the queue‘, to dramatic counter offensives in the Ukraine, to unprecedented IMF criticism of the UK government’stax-cutting plans. Perhaps time for a breather, with a wrap up data science developments in the last month.
Following is the October edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
The RSS 2022 Conference, held on 12-15 September in Aberdeen was a great success. The Data Science and AI Section’s session ‘The secret sauce of open source’ was undoubtedly a highlight (we are clearly biased!) but all in all lots of relevant, enlightening and entertaining talks for a practicing data scientist. See David Hoyle’s commentary here (also highlighted in the Members section below).
Following hot on the heels of our July meetup, ‘From Paper to Pitch‘ we were very pleased with our latest event, “IP Freely, making algorithms pay – Intellectual property in Data Science and AI” which was held on Wednesday 21 September 2022. A lively and engaging discussion was held including leading figures such as Dr David Barber (Director of the UCL Centre for Artificial Intelligence ) and Professor Noam Shemtov (Intellectual Property and Technology Law at Queen Mary’s University London).
The AI Standards Hub, an initiative that we reported on earlier this year, led by committee member Florian Ostmann, will see its official launch on 12 October. Part of the National AI Strategy, the Hub’s new online platform and activities will be dedicated to knowledge sharing, community building, strategic research, and international engagement around standardisation for AI technologies. The launch event will be livestreamed online and feature presentations and interactive discussions with senior government representatives, the Hub’s partner organisations, and key stakeholders. To join the livestream, please register before 10 October using this link (https://tinyurl.com/AIStandardsHub).
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
Sadly, we continue to see ethically and morally suspect uses of data and AI. And the potential consequences rise as the capabilities improve and use becomes more widespread.
We are still finding issues with the underlying data that drives many of the core foundation models – here it’s misclassifying bugs! Also how much personal information is hidden away and encoded in the models given the vast quantities of data used in training – really interesting piece from MIT technology review showing how GPT-3 can identify an individual.
And lots of commentary about the new image generation tools like DALLE and Stable Diffusion (more on these below) and their impact on creativity and ethics… making deep fakes easy, winning art prizes … good general summary from Axios here.
"Interactive deepfakes have the capability to impersonate people with realistic interactive behaviors, taking advantage of advances in multimodal interaction. Compositional deepfakes leverage synthetic content in larger disinformation plans that integrate sets of deepfakes over time with observed, expected, and engineered world events to create persuasive synthetic histories"
So what can be done? As we have discussed previously, there is increasing momentum around some sort of regulation and legal framework to govern AI usage
"We argue that the upcoming regulation might be particularly important in offering the first and most influential operationalisation of what it means to develop and deploy trustworthy or human-centred AI. If the EU regime is likely to see significant diffusion, ensuring it is well-designed becomes a matter of global importance.."
Implementing transparent ‘best-practices’ in model development and deployment is something we should all being doing as responsible data scientists. Good summary here of why this is important, and an excellent Best Practices for ML Engineering here (also here with video)… definitely worth a detailed read!
"Most of the problems you will face are, in fact, engineering problems. Even with all the resources of a great machine learning expert, most of the gains come from great features, not great machine learning algorithms. So, the basic approach is:
1. make sure your pipeline is solid end to end
2. start with a reasonable objective
3. add commonsense features in a simple way
4. make sure that your pipeline stays solid.
This approach will make lots of money and/or make lots of people happy for a long period of time. Diverge from this approach only when there are no more simple tricks to get you any farther. Adding complexity slows future releases."
Finally, we can also try and build ‘fairness’ into the underling algorithms, and machine learning approaches. For instance, this looks to be an excellent idea – FairGBM
"FairGBM is an easy-to-use and lightweight fairness-aware ML algorithm with state-of-the-art performance on tabular datasets.
FairGBM builds upon the popular LightGBM algorithm and adds customizable constraints for group-wise fairness (e.g., equal opportunity, predictive equality) and other global goals (e.g., specific Recall or FPR prediction targets)."
Developments in Data Science Research…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
Before delving into this month’s array of arxiv papers, I found this useful – it’s a guide to reading AI research papers… what to focus on based on what you are looking to accomplish.
The implications of the ‘chinchilla’ paper (discussed last month, highlighting the ‘under training’ of current large models) are still reverberating in the research community. One outcome is an argument for a more rigorous measurement methodology, focused on extrapolated (rather than interpolated) loss.
As always lots of research focused on making everything more efficient:
"Even the largest neural networks make errors, and once-correct predictions can become invalid as the world changes. Model editors make local updates to the behavior of base (pre-trained) models to inject updated knowledge or correct undesirable behaviors"
A few more applied examples this month:
Innovative- casting audio generation as a language modelling task – AudioLM
"We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models"
DeepMind have released Menagerie – “a collection of high-quality models for the MuJoCo physics engine”: looks very useful for anyone working with physics simulators
Finally, another great stride for the open source community this time from LAION – a large scale open source version of CLIP (a key component of image generation models that computes representations of images and texts to measure similarity)
We replicated the results from openai CLIP in models of different sizes, then trained bigger models. The full evaluation suite on 39 datasets (vtab+) are available in this results notebook and show consistent improvements over all datasets.
Stable-Dal-Gen oh my…
Lots of discussion about the new breed of text-to-image models (type in a text prompt/description and an -often amazing- image is generated) with three main models available right now: DALLE2 from OpenAI, Imagen from Google and the open source Stable-Diffusion from stability.ai.
Ok, so what’s it all about- probably the quickest way to get a feel for it is to sign up for free here and play around in the browser.
Why is it a big deal? Well, its technically very impressive… but it has the business/investment community excited about potential applications…
If you want to get a bit more ‘under the hood’, there are an ever growing number of notebooks and simple implementation guides for running in the cloud or even locally (e.g command line, in jupyterlab, in colab…)
If you want to dig into the details of how these models work, then there are some good survey papers out there specifically on diffusion models (generating the images – here and here) as well as multi-modal machine learning in general
"minGPT tries to be small, clean, interpretable and educational, as most of the currently available GPT model implementations can a bit sprawling. GPT is not a complicated model and this implementation is appropriately about 300 lines of code (see mingpt/model.py). All that's going on is that a sequence of indices feeds into a Transformer, and a probability distribution over the next index in the sequence comes out. The majority of the complexity is just being clever with batching (both across examples and over sequence length) for efficiency."
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
"By using our latest AI model, Multitask Unified Model (MUM), our systems can now understand the notion of consensus, which is when multiple high-quality sources on the web all agree on the same fact. Our systems can check snippet callouts (the word or words called out above the featured snippet in a larger font) against other high-quality sources on the web, to see if there’s a general consensus for that callout, even if sources use different words or concepts to describe the same thing. We've found that this consensus-based technique has meaningfully improved the quality and helpfulness of featured snippet callouts."
“One of the motivations of this work was our desire to study systems that learn models of datasets that is represented in a way that humans can understand. Instead of learning weights, can the model learn expressions or rules? And we wanted to see if we could build this system so it would learn on a whole battery of interrelated datasets, to make the system learn a little bit about how to better model each one"
"Deep learning is sometimes referred to as “representation learning” because its strength is the ability to learn the feature extraction pipeline. Most tabular datasets already represent (typically manually) extracted features, so there shouldn’t be a significant advantage using deep learning on these."
“We’re not trying to re-create the brain,” said David Ha, a computer scientist at Google Brain who also works on transformer models. “But can we create a mechanism that can do what the brain does?”
"A common finding is that with the right representation, the problem becomes much easier. However, how to train the neural network to learn useful representations is still poorly understood. Here, causality can help. In causal representation learning, the problem of representation learning is framed as finding the causal variables, as well as the causal relations between them.."
"As we’ve seen, the nature of algorithms requires new types of tradeoff, both at the micro-decision level, and also at the algorithm level. A critical role for leaders is to navigate these tradeoffs, both when the algorithm is designed, but also on an ongoing basis. Improving algorithms is increasingly a matter of changing rules or parameters in software, more like tuning the knobs on a graphic equalizer than rearchitecting a physical plant or deploying a new IT system"
"Lucas concludes his essay by stating that the characteristic attribute of human minds is the ability to step outside the system. Minds, he argues, are not constrained to operate within a single formal system, but rather they can switch between systems, reason about a system, reason about the fact that they reason about a system, etc. Machines, on the other hand, are constrained to operate within a single formal system that they could not escape. Thus, he argues, it is this ability that makes human minds inherently different from machines."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 65 people in England have Covid- definitely better than last month (1 in 45) but sadly starting to go in the wrong direction (was 1 in 75 two weeks ago)… and till a far cry from the 1 in 1000 we had last summer.
David Hoyle has published an excellent review of the recent RSS conference, highlighting the increasing relevance to practicing Data Scientists- well worth a read
The ONS are keen to highlight the last of this year’s ONS – UNECE Machine Learning Groups Coffee and Coding session on 2 November 2022 at 1400 – 1530 (CEST) / 0900 – 1030 (EST) when Tabitha Williams and Brittny Vongdara from Statistics Canada will provide an interactive lesson on using GitHub, and an introduction to Git. For more information and to register, please visit the Eventbrite page (Coffee and Coding Session 2 November). Any questions, get in touch at ML2022@ons.gov.uk
Jobs!
The Job market is a bit quiet over the summer- let us know if you have any openings you’d like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
I hope you have all been enjoying a great summer. Certainly lots to engage with from heat waves, sewage spills, leadership elections, spiralling energy costs… and of course on a much more positive note the Lionesses winning the Euros for the first time (it’s come home…)! Apologies for skipping a month but it does mean we have plenty to talk about so prepare for a somewhat longer than normal read…
Following is the September edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Committee members continue to be actively involved in the Alliance for Data Science Professionals, a joint initiative between the RSS and various other relevant organisations in defining standards for data scientist accreditation. The first tranche of data scientists to complete the new defined standard of professionalism received their awards at a special ceremony at the Royal Society in July. The U. K’s National Statistician welcomed the initiative.
Our recent event “From paper to pitch, success in academic/industry collaboration” which took place on Wednesday 20th July was very successful with strong attendance and a thought provoking and interactive discussion- may thanks to Will Browne for organising. We will write up a summary and publish shortly.
We also excited to announce our next event catchily titled “IP Freely, making algorithms pay – Intellectual property in Data Science and AI” which will be held on Wednesday 21 September 2022, 7.00PM – 8.00PM. Sign up here to hear leading figures such as Dr David Barber (Director of the UCL Centre for Artificial Intelligence ) and Professor Noam Shemtov (Intellectual Property and Technology Law at Queen Mary’s University London) in what should be an excellent discussion.
The RSS 2022 Conference is rapidly approaching (12-15 September in Aberdeen). The Data Science and AI Section is running what will undoubtedly be the best session(!) … ‘The secret sauce of open source’, which will discuss using open source to bridge the gap between academia and industry.
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
We know how good AI is now getting with image recognition, generation and natural language tasks. As always these technical innovations create opportunities and challenges as this thoughtful NYTimes pieces talks to.
But all these tools are trained on data- fine when it’s facts, figures and publicly available information, but how should we think about art generated ‘in the style of’ another artist?
Good morning to everyone, especially the Facebook https://t.co/EkwTpff9OI researchers who are going to have to rein in their Facebook-hating, election denying chatbot today pic.twitter.com/wMRBTkzlyD
We have to acknowledge that many of the new AI tools are astonishing both in their performance and their sophistication and that it is incredibly hard if not impossible to eliminate all mistakes. However, applying best practice and using high quality data sets should be at the core of all work in this area.
"“They were claiming near-perfect accuracy, but we found that in each of these cases, there was an error in the machine-learning pipeline,” says Kapoor."
Investment and interest in new applications is still increasing (“NATO launches innovation fund“) – so how do we make sure these increasingly opaque models are built in the right way? Increasingly some sort of regulation and auditing seems essential.
"The new Vehicle General Safety Regulation starts applying today. It introduces a range of mandatory advanced driver assistant systems to improve road safety and establishes the legal framework for the approval of automated and fully driverless vehicles in the EU"
And it’s not just regulation and auditing of new use cases and approaches that are needed. Meta/Facebook continues to come under scrutiny for current and historic practices
"Facebook’s stated mission is “to give people the power to build community and bring the world closer together.” But a deeper look at their business model suggests that it is far more profitable to drive us apart. By creating “filter bubbles”—social media algorithms designed to increase engagement and, consequently, create echo chambers where the most inflammatory content achieves the greatest visibility—Facebook profits from the proliferation of extremism, bullying, hate speech, disinformation, conspiracy theory, and rhetorical violence"
The recent overturning of Roe v Wade by the US Supreme Court and implications on the legality of abortion at the individual state level, has led to increased focus on the implications of data gathering.
“We remain committed to protecting our users against improper government demands for data, and we will continue to oppose demands that are overly broad or otherwise legally objectionable,” Ms. Fitzpatrick wrote.
And sadly data leaks continue to happen, at seemingly larger and larger scale…
"He posted again on Twitter later in the day, saying: "apparently, this exploit happened because the gov developer wrote a tech blog on CSDN and accidentally included the credentials", referring to the China Software Developer Network."
"This paper first discusses what humanoid robots are, why and how humans tend to anthropomorphise them, and what the literature says about robots crowding out human relations. It then explains the ideal of becoming “fully human”, which pertains to being particularly moral in character."
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
Solving proteins…
We have previously discussed the groundbreaking work of DeepMind in solving the protein folding problem with AlphaFold, which can generate the estimated 3d structure for any protein. They have now gone a step further and publicly released the structures of of over 200m proteins
Lots of background and commentary on this ground breaking step here and here
"Prof Dame Janet Thornton, the group leader and senior scientist at the European Molecular Biology Laboratory’s European Bioinformatics Institute, said: “AlphaFold protein structure predictions are already being used in a myriad of ways. I expect that this latest update will trigger an avalanche of new and exciting discoveries in the months and years ahead, and this is all thanks to the fact that the data are available openly for all to use."
How should we think about the relationship between the size of a model, and the size of the data set it is trained on for a given computational budget? Is there some sort of optimal relationship between the two? Researchers at DeepMind think so, and conclude (the ‘Chinchilla’ paper) that the current set of large language models are actually under-trained. (Interesting twitter discussion on scale here)
Graph Methods can be very successful at utilising features harder to represent in more traditional approaches and their application continues to expand
Ever since I found multiple single variable models combined together outperformed a single model using all the variables I’ve been sold on the concept of ensemble models… Model Soup (paper here) looks interesting- averaging weights instead of averaging outputs.
With model complexity continuing to increase, methods to interpret to model structure and reasoning are increasingly important, particular in the context of transparency. Good survey paper here
Results show that tree-based models remain state-of-the-art on medium-sized data (∼10K samples) even without accounting for their superior speed. To understand this gap, we conduct an empirical investigation into the differing inductive biases of tree-based models and Neural Networks (NNs). This leads to a series of challenges which should guide researchers aiming to build tabular-specific NNs: 1. be robust to uninformative features, 2. preserve the orientation of the data, and 3. be able to easily learn irregular functions
Finally another phenomenon I find pretty extraordinary… “Grokking” where model performance improves after a seemingly over-fitting. Researchers at Apple give the full story
"The grokking phenomenon as reported by Power et al. ( arXiv:2201.02177 ) refers to a regime where a long period of overfitting is followed by a seemingly sudden transition to perfect generalization. In this paper, we attempt to reveal the underpinnings of Grokking via a series of empirical studies. Specifically, we uncover an optimization anomaly plaguing adaptive optimizers at extremely late stages of training, referred to as the Slingshot Mechanism"
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
We talk a lot about Large Language models like GPT3 and how good they are becoming – but what are the real like applications for them?
Of course Large Language Models are a key component of Multi Modal Models (combining data from different modalities like images and text) such as DALLE which continue to generate lots of interest
This is well worth listening too- how DALLE Works on the The Data Exchange. Really interesting to understand the components (LLM, CLIP, diffusion models to generate the output).(OpenAI have also published commentary of some of their risk reduction techniques mentioned in the discussion)
With the proliferation of data readily available, spurious correlations are an increasing problem which explains the growing interest in causal inference
Many real-world machine learning problems can be framed as graph problems. On online platforms, users often share assets (e.g. photos) and interact with each other (e.g. messages, bookings, reviews). These connections between users naturally form edges that can be used to create a graph.
However, in many cases, machine learning practitioners do not leverage these connections when building machine learning models, and instead treat nodes (in this case, users) as completely independent entities. While this does simplify things, leaving out information around a node’s connections may reduce model performance by ignoring where this node is in the context of the overall graph.
Elegant approach to matching supply and demand in energy markets (the ‘unit commitment problem’) – hugely beneficial for the utilisation of variable green energy sources like solar and wind.
"To conclude: we have shown that for in the presence of (many) irrelevant variables, RF performance suffers and something needs to be done. This can be either tuning the RF, most importantly increasing the mtry parameter, or identifying and removing the irrelevant features using the RFE procedure rfe() part of the caret package in R. Selecting only relevant features has the added advantage of providing insight into which features contain the signal."
Identifying when your models decay through changing (drifting) data is critical to maintaining model performance
"Text Embeddings give you the ability to turn unstructured text data into a structured form. With embeddings, you can compare two or more pieces of text, be it single words, sentences, paragraphs, or even longer documents. And since these are sets of numbers, the ways you can process and extract insights from them are limited only by your imagination."
There are so many options now for ML/Data Science platforms that it can be very hard to know where to start if you are looking to evolve how you work. So it’s always useful to see what other innovative companies use:
If you are experimenting with the ever expanding list of autoML tools, this could be very useful– a comprehensive way of benchmarking across a variety of different problems
This looks interesting – DeepChecks, “testing and validating your machine learning models and data”
"As these LLMs become more common and powerful, there seems to be less and less agreement over how we should understand them. These systems have bested many “common sense” linguistic reasoning benchmarks over the years, many which promised to be conquerable only by a machine that “is thinking in the full-bodied sense we usually reserve for people.” Yet these systems rarely seem to have the common sense promised when they defeat the test and are usually still prone to blatant nonsense, non sequiturs and dangerous advice. This leads to a troubling question: how can these systems be so smart, yet also seem so limited?"
"To be sure, there are indeed some ways in which AI truly is making progress—synthetic images look more and more realistic, and speech recognition can often work in noisy environments—but we are still light-years away from general purpose, human-level AI that can understand the true meanings of articles and videos, or deal with unexpected obstacles and interruptions. We are still stuck on precisely the same challenges that academic scientists (including myself) having been pointing out for years: getting AI to be reliable and getting it to cope with unusual circumstances."
"Ongoing debates about whether large pre-trained models understand text and images are complicated by the fact that scientists and philosophers themselves disagree about the nature of linguistic and visual understanding in creatures like us. Many researchers have emphasized the importance of “grounding” for understanding, but this term can encompass a number of different ideas. These might include having appropriate connections between linguistic and perceptual representations, anchoring these in the real world through causal interaction, and modeling communicative intentions. Some also have the intuition that true understanding requires consciousness, while others prefer to think of these as two distinct issues. No surprise there is a looming risk of researchers talking past each other."
Liberating the world’s scientific knowledge from the twin barriers of accessibility and understandability will help drive the transition from a web focused on clicks, views, likes, and attention to one focused on evidence, data, and veracity. Pharma is clearly incentivized to bring this to fruition, hence the growing number of startups identifying potential drug targets using AI — but I believe the public, governments, and anyone using Google might be willing to forgo free searches in an effort for trust and time-saving. The world desperately needs such a system, and it needs it fast
"To put this in context: until this paper, it was conventional to train all large LMs on roughly 300B tokens of data. (GPT-3 did it, and everyone else followed.)
Insofar as we trust our equation, this entire line of research -- which includes GPT-3, LaMDA, Gopher, Jurassic, and MT-NLG -- could never have beaten Chinchilla, no matter how big the models got[6].
People put immense effort into training models that big, and were working on even bigger ones, and yet none of this, in principle, could ever get as far Chinchilla did."
Fun Practical Projects and Learning Opportunities A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 45 people in England have Covid- a little better than last month (1 in 30) and at least down on it’s peak when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
Kevin O’Brien highlights the PyData Global 2022 Conference, taking place online between Thurs 1st and Sat 3rd December. Calls for proposals are still open until September 12th, 2022. Submit here.
Ronald Richman and colleagues have published a paper on their innovative work using deep neural nets for discrimination free pricing in insurance, when discriminatory characteristics are not known. Well worth a read.
Mark Marféand Cerys Wyn Davies recently published an article about data and IP issues in the context of AI deployed on ESG projects which looks interesting and relevant.
Finally, more news from The Data Science Campus who are helping organise this year’s UN Big Data Hackathon, November 8-11.
The UN Big Data Hackathon is an exciting global competition for data professionals and young people from all around the world to work together on important global challenges.
It’s part of this year’s UN Big Data conference in Indonesia. There are two tracks, one for data science professionals and the other for young people and students (under 32 years of age).
Registrations should preferably be done as a team of 3 to 5 people, but individual applications can also be accepted. Registration deadline in Sept 15th.
Jobs!
The Job market is a bit quiet over the summer- let us know if you have any openings you’d like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
From paper to pitch : success stories of academic and industry collaboration.
Next Wednesday (Wednesday 20 July 2022, 7.00PM – 9.00PM) the RSS Data Science and AI section are hosting an event to bring together practitioners and researchers to improve collaboration.
We have two excellent speakers in Rebecca Pope, Ph.D. (she/her) and Andre Vauvelle. It will be great opportunity to discuss how we can bring industry and academia together and it would be lovely to see people in person again.
The event is free, but there are limited places, so please sign up here. Looking forward to seeing you all!
Welcome to July! Inflation, union strikes, sunshine … lots of commentary drawing parallels to the mid-70s. One thing that is very different from that period is the world of data science (which didn’t even exist as a discipline) – crazy to think that the Apple II launched in ’77 with 4 KB RAM, 4 million times less memory than the laptop I’m writing this on…
Following is the July edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. We’ll take a break in August, so fingers crossed this sees you through to the beginning of September…
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with plans underway to launch the Advanced Certificate shortly.
We are very excited to announce our next meetup, “From paper to pitch, success in academic/industry collaboration” which will take place on Wednesday 20th July from 7pm-9pm. We believe that there is huge potential in greater collaboration between industry and academia and have invited two excellent speakers to provide examples of how this can work in practice. This should be a thought provoking, and very relevant (and free) event – sign up here.
The full programme is now available for the September RSS 2022 Conference. The Data Science and AI Section is running what will undoubtedly be the best session(!) … ‘The secret sauce of open source’, which will discuss using open source to bridge the gap between academia and industry.
As mentioned last time, Janet Bastiman (Chief Data Scientist at Napier AI) recently spoke at the FinTech FinCrime Exchange Conference (FFECON) in a panel session entitled “With great AI power comes great FinCrime responsibility”: cool summary from the discussion…
"From California to Colorado and Pennsylvania, as child welfare agencies use or consider implementing algorithms, an AP review identified concerns about transparency, reliability and racial disparities in the use of the technology, including their potential to harden bias in the child welfare system."
Also some interesting developments and frameworks from the research community:
An approach to try and codify the ‘values’ that are encoded in a machine learning model, making it easier to identify appropriate use-cases and potential pitfalls
The Large Language Models (such as GPT3 – good background from the economist on foundation models here) that underly much of the recent breakthroughs in natural language processing and applications such as chat-bots are trained on vast quantities of text. By focusing the training on particular types of text, you can, relatively easily, produce models with certain “character”
"In summary, GPT-4chan resulted in a large amount of public discussion and media coverage, with AI researchers generally being critical of Kilcher’s actions and many others disagreeing with these criticisms. This sequence of events was generally predictable, so much so that I was able to prompt GPT-3 – which has no knowledge whatsoever about current events – to summarize the controversy somewhat accurately"
"Cohere, OpenAI, and AI21 Labs have developed a preliminary set of best practices applicable to any organization developing or deploying large language models. Computers that can read and write are here, and they have the potential to fundamentally impact daily life.
The future of human-machine interaction is full of possibility and promise, but any powerful technology needs careful deployment. The joint statement below represents a step towards building a community to address the global challenges presented by AI progress, and we encourage other organizations who would like to participate to get in touch."
Of course the sad truth is that, in simplistic terms, this type of model is basically regurgitating the same biases present in the material it was trained on. Some thought provoking analysis from textio highlighting the inherent biases present in performance feedback.
A Google researcher (since placed on administrative leave…) caused controversy by claiming that one of these Large Language Models (in this case Google’s LaMDA) was sentient- good summary in Wired here. The guardian followed up on this with some thoughtful pieces on how the model works, and why we are prone to be fooled by mimicry.
"It’s strategic transparency. They get to come out and say they're helping researchers and they're fighting misinformation on their platforms, but they're not really showing the whole picture.”
With the proliferation of data available in the modern world, AI is often thought of as a critical tool for intelligence services to quickly identify potential threats. But the current approaches may not be the ‘silver bullet’ hoped for…
"While AI can calculate, retrieve, and employ programming that performs limited rational analyses, it lacks the calculus to properly dissect more emotional or unconscious components of human intelligence that are described by psychologists as system 1 thinking."
"China’s ambition to collect a staggering amount of personal data from everyday citizens is more expansive than previously known, a Times investigation has found. Phone-tracking devices are now everywhere. The police are creating some of the largest DNA databases in the world. And the authorities are building upon facial recognition technology to collect voice prints from the general public."
"Police can not only obtain search histories from a pregnant person’s device, but can also obtain records directly from search engines, and sometimes they don’t even need a warrant."
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
"We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models"
"To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant."
Almost by definition, improving model generalisation (ie predictions on new examples) is at the core of any research. “VOS: Learning What You Don’t Know by Virtual Outlier Synthesis” directly addresses this by focusing on detecting out of distribution examples.
"In experiments on medium-sized tabular data with about 10,000 samples, Hopular outperforms XGBoost, CatBoost, LightGBM and a state-of-the art Deep Learning method designed for tabular data"
Facebook/Meta continues to make progress in direct speech to speech which as a concept is very impressive (“these models directly translate source speech into target speech spectrograms”)
"Parti treats text-to-image generation as a sequence-to-sequence modeling problem, analogous to machine translation – this allows it to benefit from advances in large language models, especially capabilities that are unlocked by scaling data and model sizes"
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
Robots are becoming increasingly sophisticated but making them context aware is still a challenge – this looks like excellent progress (“This Warehouse Robot Reads Human Body Language“)
"Using a neural network trained on widely available weather forecasts and historical turbine data, we configured the DeepMind system to predict wind power output 36 hours ahead of actual generation. Based on these predictions, our model recommends how to make optimal hourly delivery commitments to the power grid a full day in advance"
"This was AlphaFold 2, which was published in July 2021. It had a level of atomic accuracy of less than one angstrom. I work with a lot of colleagues in structural biology. They've spent years to determine the structure of a protein and many times they never solve it. But not only do you produce confidence measures, you also — anyone — can put in their favorite protein and see how it works in seconds. And you also get feedback from the user. You also linked up with the European Bioinformatics Institute (EMBL-EBI). It's open-source and it's free."
Although there is increasing progress in quantum computing, the framing of problems in ways that can utilise the quantum approach is far from straightforward. Interesting paper showing how to do this for some simple real world examples
More DALL-E fun.. DALL-E is still making headlines so we’ll keep serving up a few fun posts!
"We discover that DALLE-2 seems to have a hidden vocabulary that can be used to generate images with absurd prompts. For example, it seems that \texttt{Apoploe vesrreaitais} means birds and \texttt{Contarra ccetnxniams luryca tanniounons} (sometimes) means bugs or pests"
How does that work? Tutorials and deep dives on different approaches and techniques
"An important point: if you train the first level on the whole dataset first and then the second level, you will get a leakage in the data. At the second level, the content score of matrix factorization will take into account the targeting information"
You’ve been wanting to explore GPT-3 but haven’t known where to start? Here you go!
"I think a big reason people have been put off trying out GPT-3 is that OpenAI market it as the OpenAI API. This sounds like something that’s going to require quite a bit of work to get started with.
But access to the API includes access to the GPT-3 playground, which is an interface that is incredibly easy to use. You get a text box, you type things in it, you press the “Execute” button. That’s all you need to know.."
I’m a regular user of Jupyter Lab (and notebooks) … but I’ve never used it build a web app! Lots of useful tips here
And … it’s live! Andrew Ng’s new foundational course in Machine Learning is open for enrolment – if you do one course, do this one
"Newly rebuilt and expanded into 3 courses, the updated Specialization teaches foundational AI concepts through an intuitive visual approach, before introducing the code needed to implement the algorithms and the underlying math."
Practical tips How to drive analytics and ML into production
How best to structure data teams across an organisation is a question that has no best answer. Certainly centralisation makes a lot of sense unless you are in a very sophisticated data savvy organisation…. Facebook have only just made the decision to decentralise
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink! A few extra this month to get you through the long summer…
"At the heart of this debate are two different visions of the role of symbols in intelligence, both biological and mechanical: one holds that symbolic reasoning must be hard-coded from the outset and the other holds it can be learned through experience, by machines and humans alike. As such, the stakes are not just about the most practical way forward, but also how we should understand human intelligence — and, thus, how we should pursue human-level artificial intelligence."
"Now it is true that GPT-3 is genuinely better than GPT-2, and maybe true that InstructGPT is genuinely better than GPT-3. I do think that for any given example, the probability of a correct answer has gone up...
...But I see no reason whatsoever to think that the underlying problem — a lack of cognitive models of the world —have been remedied. The improvements, such as they are, come, primarily because the newer models have larger and larger sets of data about how human beings use word sequences, and bigger word sequences are certainly helpful for pattern matching machines. But they still don’t convey genuine comprehension, and so they are still very easy for Ernie and me (or anyone else who cares to try) to break.
"There’s an important point about expertise hidden in here: we expect our AGIs to be “experts” (to beat top-level Chess and Go players), but as a human, I’m only fair at chess and poor at Go. Does human intelligence require expertise? (Hint: re-read Turing’s original paper about the Imitation Game, and check the computer’s answers.) And if so, what kind of expertise? Humans are capable of broad but limited expertise in many areas, combined with deep expertise in a small number of areas. So this argument is really about terminology: could Gato be a step towards human-level intelligence (limited expertise for a large number of tasks), but not general intelligence?"
And another somewhat pragmatic view using the interesting ‘language model plays chess’ example (treating chess moves as words that are fed into the model)
For those not well-versed in chess, here’s a summary of what happened. The first three or four moves were a fairly standard opening from both sides. Then, the AI began making massive blunders, even throwing away its queen. Finally, as the vice began to close around its king, the AI eventually made an illegal move, losing the game.
All in all, a pretty solid showing: it understood the format, (mostly) knew what moves were legal, and even played a decent opening. But this AI is not good at chess. Certainly, nothing close to 5000 ELO.
Is this just a “flub”, which will be fixed by scale? Will a future, even-larger GPT be the world chess champion? I don’t believe so.
"In January, 2021, Microsoft filed a patent to reincarnate people digitally through distinct voice fonts appended to lingual identities garnered from their social media accounts. I don’t see any reason why it can’t work. I believe that, if my grandchildren want to ask me a question after I’m dead, they will have access to a machine that will give them an answer and in my voice. That’s not a “new soul.” It is a mechanical tongue, an artificial person, a virtual being. The application of machine learning to natural language processing achieves the imitation of consciousness, not consciousness itself, and it is not science fiction. It is now."
Don’t worry – if we eventually get to an artificial general intelligence that everyone agrees on, we have a thoughtful taxonomy of all the ways it could kill us (AGI ruin: a list of lethalities)!
Fun Practical Projects and Learning Opportunities A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 30 people in England (1 in 18 in Scotland) have Covid. Sadly this has risen (from 1 in 60 last month) due to infections compatible with Omicron variants BA.4 and BA.5, but is at least down on it’s peak when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
Promising research on the use of fitness tracker data to detect Covid early
The ONS Data Science Campus was involved in this widely covered ONS piece on the cost of living inspired by Jack Monroe and other food campaigners.
‘Making text count: Economic forecasting using newspaper text’, which was a collaboration across multiple institutions and for which I am a co-author, was published in the journal of applied econometrics and shows how machine learning + text from newspaper can improve macroeconomic forecasts.
We released a package from the Campus for evaluating how well synthetic data matches real data. Repository here, blog post here.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
It’s June already – time flies – and in the UK an extra bank holiday! Perhaps the data science reading materials below might help fill the void now the Jubilee celebrations have finished …
Following is the June edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with a plan to launch the Advanced Certificate in the summer.
We will also shortly be announcing details of our next meetup – watch this space!
Janet Bastiman (Chief Data Scientist at Napier AI) recently spoke at the FinTech FinCrime Exchange Conference (FFECON) in a panel session entitled “With great AI power comes great FinCrime responsibility”, discussing how AI implementations can go wrong and what we need to do about it.
The RSS is running an in-person Discussion Meeting on Thursday June 16th at the Errol Street headquarters: “Statistical Aspects of the Covid-19 Pandemic”. Register here for free attendance.
The full programme is now available for the September RSS 2022 Conference. The Data Science and AI Section is running what will undoubtedly be the best session(!) … ‘The secret sauce of open source’, which will discuss using open source to bridge the gap between academia and industry. An early booking registration discount is available until 6 June for in-person attendance at the conference and 20 June for viewing content via the online conference platform.
"After three separate experiments, the researchers found the AI-created synthetic faces were on average rated 7.7% more trustworthy than the average rating for real faces... The three faces rated most trustworthy were fake, while the four faces rated most untrustworthy were real, according to the magazine New Scientist."
"The settlement, filed Monday in a federal court in Illinois, bars the company from selling its biometric data to most businesses and private firms across the U.S. The company also agreed to stop offering free trial accounts to individual police officers without their employers' knowing or approving, which had allowed them to run searches outside of police departments' purview"
"Even when you filter medical images past where the images are recognizable as medical images at all, deep models maintain a very high performance. That is concerning because superhuman capacities are generally much more difficult to control, regulate, and prevent from harming people."
"This brief focuses on three sub-areas within “AI safety,” a term that has come to refer primarily to technical research (i.e., not legal, political, social, etc. research) that aims to identify and avoid unintended AI behavior. AI safety research primarily seeks to make progress on technical aspects of the many socio-technical challenges that have come along with progress in machine learning over the past decade."
"The AI industry does not seek to capture land as the conquistadors of the Caribbean and Latin America did, but the same desire for profit drives it to expand its reach. The more users a company can acquire for its products, the more subjects it can have for its algorithms, and the more resources—data—it can harvest from their activities, their movements, and even their bodies."
"The answers are complex and depend to some extent on your exact threat models, but if you want a summary of the advice I usually give it boils down to:
- Treat your training data like you do your traditional source code.
- Treat your model files like compiled executables."
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
"Another class of specification gaming examples comes from the agent exploiting simulator bugs. For example, a simulated robot that was supposed to learn to walk figured out how to hook its legs together and slide along the ground."
How best can you incorporate domain specific information into general machine learning architectures – perhaps “embedded model flows” is the way forward.
"A lot of the existing video models have poor quality (especially on long videos), require enormous amounts of GPUs/TPUs, and can only solve one specific task at a time (only prediction, only generation, or only interpolation). We aimed to improve on all these problems. We do so through a Masked Conditional Video Diffusion (MCVD) approach."
Large Language Models are zero-shot learners … Crazy finding … “we show that LLMs are decent zero-shot reasoners by simply adding ‘Let's think step by step‘ before each answer”
How do you build functioning translation models for the long tail of languages where large bi-lingual data sets are not available? Amazingly, google as figured out how to use monolingual data alone (i.e. text in one language without translation into another) using transfer learning and deep embeddings.
A much broader segment of the AI community needs access to these models in order to conduct reproducible research and collectively drive the field forward. With the release of OPT-175B and smaller-scale baselines, we hope to increase the diversity of voices defining the ethical considerations of such technologies.
DeepMind has been at its ground breaking best again …
Firstly with Flamingo which elegantly combines visual and text user feedback to refine responses
And perhaps most impressively with Gato, a single generalist agent
The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
Real world applications of reinforcement learning can still be hard to come by despite the progress at DeepMind. One promising approach is Offline RL (which utilises historic data) – looks like BAIR (Berkley Artificial Intelligence Research) has made good progress
"Let’s begin with an overview of the algorithm we study. While lots of prior work (Kumar et al., 2019; Ghosh et al., 2021; and Chen et al., 2021) share the same core algorithm, it lacks a common name. To fill this gap, we propose the term RL via Supervised Learning (RvS). We are not proposing any new algorithm but rather showing how prior work can be viewed from a unifying framework"
By the way- some more good (and accessible) stuff from BAIR
We are doing dating all wrong … so says the data – apparently success is much more tied to your characteristics at the time and has little to do with your potential partner.. well structured article.
Advocates like Mr. Ward look to beneficial, low-cost, intermediate technologies that are available now. A prime example is intelligent speed assistance, or I.S.A., which uses A.I. to manage a car’s speed via in-vehicle cameras and maps. The technology will be mandatory in all new vehicles in the European Union beginning in July, but has yet to take hold in the United States.
At Google, we’re always dreaming up new ways to help you uncover the information you’re looking for — no matter how tricky it might be to express what you need. That’s why today, we’re introducing an entirely new way to search: using text and images at the same time. With multisearch in Lens, you can go beyond the search box and ask questions about what you see.
No scary-dog robots this month … but record leaps!
More DALL-E fun.. A one off section on everyone’s favourite image generation tool, DALL-E
Last month we highlighted the amazing examples of images generated from text prompts using OpenAI’s DALL-E 2. There’s been lots more commentary so we’ve pulled it together in one place…
First of all, an update from OpenAI – apparently early users have generated over 3m images to date.
How does it actually work- good breakdown of the underlying methods here.
A different take on DALL-E and what it means for design and a potential ‘vibe-shift’ – well worth a read.
"Graphs are a convenient way to abstract complex systems of relations and interactions. The increasing prominence of graph-structured data from social networks to high-energy physics to chemistry, and a series of high-impact successes have made deep learning on graphs one of the hottest topics in machine learning research"
"Recommender systems work well when we have a lot of data on user-item preferences. With a lot of data, we have high certainty about what users like. Conversely, with very little data, we have low certainty. Despite the low certainty, recommenders tend to greedily promote items that received higher engagement in the past. And because they influence how much exposure an item gets, potentially relevant items that aren’t recommended continue getting no to low engagement, perpetuating the feedback loop."
Intriguing approach – ‘supervised’ clustering using SHAP values. When you don’t have a supervised model, you just build one on a somewhat arbitrary dependent variable!
It has been some time since we did some proper maths… get the cold cloth and a strong cup of coffee and lean in!
Structural optimisation (with code from scratch)- interesting to see what applications of this approach their might be outside of ‘building structures’
"The goal of structural optimization is to place material in a design space so that it rests on some fixed points or “normals” and resists a set of applied forces or loads as efficiently as possible."
"This article outlines different methods for creating confidence intervals for machine learning models. Note that these methods also apply to deep learning. This article is purposefully short to focus on the technical execution without getting bogged down in details; there are many links to all the relevant conceptual explanations throughout this article."
Different embedding approaches (and not a mention of Word2Vec)…
Finally, Andrew Ng is launching his new revamped ML specialisation… (the original course has been enrolled by an astonishing 4.8m people) – for a simple walk though of the key machine learning techniques have a read of his latest ‘Batch’ newsletter
"My team spent many hours debating the most important concepts to teach. We developed extensive syllabi for various topics and prototyped course units in them. Sometimes this process helped us realize that a different topic was more important, so we cut material we had developed to focus on something else. The result, I hope, is an accessible set of courses that will help anyone master the most important algorithms and concepts in machine learning today — including deep learning but also a lot of other things — and to build effective learning systems."
Practical tips How to drive analytics and ML into production
"For example, when you’re in a BI tool like Looker, you inevitably think, “Do I trust this dashboard?” or “What does this metric mean?” And the last thing anyone wants to do is open up another tool (aka the traditional data catalog), search for the dashboard, and browse through metadata to answer that question.."
"I actually don’t care that much about the bundling argument that I will make in this post. Truthfully, I just want to argue that feature stores, metrics layers, and machine learning monitoring tools are all abstraction layers on the same underlying concepts, and 90% of companies should just implement these “applications” in SQL on top of streaming databases."
"At its core, data storytelling is about taking the step beyond the simple relaying of data points. It’s about trying to make sense of the world and leveraging storytelling to present insights to stakeholders in a way they can understand and act on. As data scientists, we can inform and influence through data storytelling by creating personal touch points between our audience and our analysis."
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink!
"But this morning I woke to a new reification, a Twitter thread that expresses, out loud, the Alt Intelligence creed, from Nando de Freitas, a brilliant high-level executive at DeepMind, Alphabet’s rightly-venerated AI wing, in a declaration that AI is “all about scale now.” Indeed, in his mind (perhaps deliberately expressed with vigor to be provocative), the harder challenges in AI are already solved. “The Game is Over!”, he declares"
"It is a tale told by an idiot, full of sound and fury, signifying nothing". —Macbeth
"AI-generated artwork is the same as a gallery of rock faces. It is pareidolia, an illusion of art, and if culture falls for that illusion we will lose something irreplaceable. We will lose art as an act of communication, and with it, the special place of consciousness in the production of the beautiful."
"AIs will make increasingly complex and important decisions, but they may make these decisions based on different criteria that could potentially go against our values. Therefore, we need a language to talk to AI for better alignment. "
"But the algorithmic summaries could make errors, include outdated information or remove nuance and uncertainty, without users appreciating this. If anyone can use LLMs to make complex research comprehensible, but they risk getting a simplified, idealized view of science that’s at odds with the messy reality, that could threaten professionalism and authority. It might also exacerbate problems of public trust in science."
Fun Practical Projects and Learning Opportunities A few fun practical projects and topics to keep you occupied/distracted:
The latest results from the ONS tracking study estimate 1 in 60 people in England have Covid. This is at least moving in the right direction compared to couple of weeks ago, when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
Jencir Lee has published the first release of his Time Series Terminal – more details at https://tsterm.com and also the white paper with promising research results here
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Another month flies by, and although we had that rarest of occasions in the UK – a sunny Easter weekend – the news in general continues to be depressing: law breakers at the highest ranks of government, covid infections high, and of course the devastating war in Ukraine. Hopefully the data science reading materials below might distract a little…
Following is the May edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We have all been shocked and saddened by events in the Ukraine and our thoughts and best wishes go out to everyone affected
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with a plan to launch the Advanced Certificate in the summer.
Florian Ostmann (Head of AI Governance and Regulatory Innovation at The Alan Turing Institute) continues to work on setting up the AI Standards Hub pilot. As set out in the previously shared announcement, this new initiative aims to promote awareness and understanding of the role of technical standards as an AI governance and innovation mechanism, and to grow UK stakeholder involvement in international AI standardisation efforts. The AI Standards Hub team have set up an online form to sign up for updates about the initiative (including a notification when the newly developed AI Standards Hub website goes live) and an opportunity to provide feedback to inform the Hub’s strategy. The form can be accessed at www.aistandardshub.org. If you are interested to learn more about the initiative, you can also watch a recording of the recent AI UK session about the AI Standards Hub here.
The next RSS DMC (Discussion Meetings Committee) is holding their next Discussion Meeting on 11th May 3-5pm BST held online (with the DeMO at 2pm), discussing the paper ‘Vintage Factor Analysis with Varimax Performs Statistical Inference’ – all welcome
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
We’ve discussed previously the increasing ease with which realistic ‘fakes’ (profiles, images, videos…) can be generated. It’s quite hard to estimate the scale of the problem though, as we are likely increasingly unaware of most instances we come across. Two Stanford University researchers have attempted to shed some light, uncovering over 1,000 AI-generated LinkedIn faces across 70 different businesses:
"It's not a story of mis- or disinfomation, but rather the intersection of a fairly mundane business use case w/AI technology, and resulting questions of ethics & expectations. What are our assumptions when we encounter others on social networks? What actions cross the line to manipulation"
"The image recognition app botched its task, Mr. Monteith said, because it didn’t have proper training data. Ms. Edmo explained that tagging results are often “outlandish” and “offensive,” recalling how one app identified a Native American person wearing regalia as a bird. And yet similar image recognition apps have identified with ease a St. Patrick’s Day celebration, Ms. Ardalan noted as an example, because of the abundance of data on the topic."
Under-representation of minority groups is a key challenge for the US Census, which is a critical problem as many government decisions (from voting districts to funding) are based on the census figures. Excellent Wired article digging into these challenges and whether ML approaches to understanding satellite imagery can help.
"While women are more likely to write biographies about other women, Wikimedia’s Community Insights 2021 Report, which covers the previous year, found that only 15 percent of Wikipedia editors identified as women. This leaves women overlooked and underrepresented, despite the enormous impact they’ve had throughout history in science, entrepreneurship, politics, and every other part of society."
"These modes of research require organizations that can gather a lot of data, data that is often collected via ethically or legally questionable technologies, like surveilling people in nonconsensual ways. If we want to build technology that has meaningful community input, then we need to really think about what’s best. Maybe AI is not the answer for what some particular community needs."
"We argue that for the NAIRR to meet its goal of supporting non-commercial AI research, its design must take into account what we predict will be another closely related trend in AI R&D: an increasing reliance on large pre-trained models, accessed through application programming interfaces (APIs)."
Finally some commentary and a more in depth review (from the Ada Lovelace Institute) of the European Commission proposal for the Artificial Intelligence Act (‘the AI Act’)
"An analysis of the Act for the U.K.-based Ada Lovelace Institute by a leading internet law academic, Lilian Edwards, who holds a chair in law, innovation and society at Newcastle University, highlights some of the limitations of the framework — which she says derive from it being locked to existing EU internal market law; and, specifically, from the decision to model it along the lines of existing EU product regulations."
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
Recently, Google has been crushing it on the research front!
Matrix Factorisation is still a very useful and efficient approach to a number of ML tasks (e.g. collaborative filtering for recommender systems). Scaling has been a problem in the past, but maybe not so much anymore…“Large Scale Matrix Factorisation on TPUs”
You can’t build large language models without incredible amounts of compute power – something we have covered previously that puts this type of research out of the reach of most people. But you also can’t do it without data – and Google have at least helped a little in this space by releasing CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus (dated 1st April but I’m pretty sure it’s not an April Fool…)
"We evaluated PaLM on 29 widely-used English natural language processing (NLP) tasks. PaLM 540B surpassed few-shot performance of prior large models, such as GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla, and LaMDA, on 28 of 29 of tasks that span question-answering tasks (open-domain closed-book variant), cloze and sentence-completion tasks, Winograd-style tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and natural language inference tasks."
ML models typically produce an answer, but getting a feel for the confidence we should have an the answer, or a confidence range around it, is often difficult – useful paper looking into uncertainties
Many ML approaches use regularisation as well as data augmentation to try and prevent over-fitting and improve generalisation- research from Meta/Facebook highlighting how important it is to assess the effects at a class level (as well as overall)
"Those results demonstrate that our search for ever
increasing generalization performance -averaged over all classes and samples- has left us with models
and regularizers that silently sacrifice performances on some classes. This scenario can become dangerous when deploying a model on downstream tasks"
I’m always paranoid about overfitting models, and intrigued by phenomena such as double decent, where, on very large data sets, you can find test set performance improve long after you think you have trained too far. OpenAI have been exploring similar phenomena on smaller data sets (‘Grokking’ – paper here) which could be very powerful.
This is pretty amazing – DiffusionClip from Korea Advanced Institute of Science and Technology: “zero shot image manipulation guided by text prompts”! And you can play around with it in pyTorch – repo here
I still struggle getting Deep Learning techniques to perform well (or better than tree based approaches) on traditional tabular data – useful survey on this topic here, and again good to see the repo here
Does AI make human decision making better? Yes, it looks like. Interesting analysis: using AlphaGo to evaluate Go player moves before and after the release of the system from DeepMind.
"Our analysis of 750,990 moves in 25,033 games by 1,242 professional players reveals that APGs significantly improved the quality of the players’ moves as measured by the changes in winning probability with each move. We also show that the key mechanisms are reductions in the number of human errors and in the magnitude of the most critical mistake during the game. Interestingly, the improvement is most prominent in the early stage of a game when uncertainty is higher"
"In this paper, we train Transformers
to infer the function or recurrence relation underlying sequences of integers or oats, a typical task in
human IQ tests which has hardly been tackled in the
machine learning literature. We evaluate our integer
model on a subset of OEIS sequences, and show that it
outperforms built-in Mathematica functions for recurrence prediction"
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
Not to be outdone by Google, OpenAI released DALL-E 2 providing some jaw-dropping examples of generating realistic images from text prompts
Some excellent commentary from TheVerge here including: – details of some of the new features like ‘in-painting’ (allowing editing of pictures); – how it works (building on and improving CLIP – similar to the DiffusionCLIP paper discussed above); – and also some of the safeguards built in in an attempt to prevent miss-use (“As a preemptive anti-abuse feature, the model also can’t generate any recognisable faces based on a name “)
A dig into how it performs from LessWrong here: some amazing examples although best to steer clear of text and smaller objects
"Overall this is more powerful, flexible, and accurate than the previous best systems. It still is easy to find holes in it, with with some patience and willingness to iterate, you can make some amazing images."
In terms of real world impact, DeepMind’s AlphaFold’s ability to predict protein structures has already proven hugely beneficial, and it seems we are only just scratching the surface of its potential – good paper in Nature
“AlphaFold changes the game,” says Beck. “This is like an earthquake. You can see it everywhere,” says Ora Schueler-Furman, a computational structural biologist at the Hebrew University of Jerusalem in Israel, who is using AlphaFold to model protein interactions. “There is before July and after.”
Medical image diagnostics seems like a natural fit for many of the image based AI techniques. There have been lots of positive studies but challenges getting the systems into widespread use. This feels like a positive step – official certification for Oxipit’s autonomous AI imaging suite
"When applied to the data sets taken from the Long Beach area, the algorithms detected substantially more earthquakes and made it easier to work out how and where they started. And when applied to data from a 2014 earthquake in La Habra, also in California, the team observed four times more seismic detections in the “denoised” data compared with the officially recorded number."
Are animators’ jobs the next in line for AI replacement? Ubisoft has unveiled ‘ZooBuilder’ which “recreates accurate animated skeletons of various animals by analysing video footage”.
Introducing ZooBuilder, an AI tool developed at @UbisoftLaForge to mimic wildlife and create unique and immersive worlds without the need for mo-cap 🐅⬇ pic.twitter.com/jToxcoR5th
Fully autonomous vehicles risk becoming the next Nuclear Fusion… always on the horizon but never quite realised. Waymo (Google’s subsidiary) announced a significant step though with their testing in San Fransisco
"This morning in San Francisco, a fully autonomous all-electric Jaguar I-PACE, with no human driver behind the wheel, picked up a Waymo engineer to get their morning coffee and go to work. Since sharing that we were ready to take the next step and begin testing fully autonomous operations in the city, we’ve begun fully autonomous rides with our San Francisco employees. They now join the thousands of Waymo One riders we’ve been serving in Arizona, making fully autonomous driving technology part of their daily lives."
And it’s been a month or two since our last ‘slightly scary robot dog’ video… so here we go. This time learning to run very fast using a completely new (and ungainly running technique)
"Yeah, OK, what you’re looking at in the video above isn’t the most graceful locomotion. But MIT scientists announced last week that they got this research platform, a four-legged machine known as Mini Cheetah, to hit its fastest speed ever—nearly 13 feet per second, or 9 miles per hour—not by meticulously hand-coding its movements line by line, but by encouraging digital versions of the machine to experiment with running in a simulated world"
How does that work? A new section on understanding different approaches and techniques
Contrastive learning is pretty cool- it trains models on the basis of the relationships between examples rather than the examples themselves and underpins some of the recent advances in learning visual representations (e.g. DALL-E, CLIP). But how does it work?- good tutorial here
How do Graph Neural Networks actually work? Excellent detailed tutorial here complete with fun hand-drawn diagrams…
This is very elegant – an in-browser visualisation of neural net activations, definitely worth playing around with
"While teaching myself the basics of neural networks, I was finding it hard to bridge the gap between the foundational theory and a practical "feeling" of how neural networks function at a fundamental level. I learned how pieces like gradient descent and different activation functions worked, and I played with building and training some networks in a Google Colab notebook.
Despite the richness of the ecosystem and the incredible power of the available tools, I felt like I was missing a core piece of the puzzle in my understanding."
"The paper, which was inspired by a short comment in McElreath's book (first edition), shows that theta does not necessarily change much even if you get a significant result. The probability theta can change dramatically under certain conditions, but those conditions are either so stringent or so trivial that it renders many of the significance-based conclusions in psychology and psycholinguistics questionable at the very least."
"It's no secret that good analyses are often the result of very scattershot and serendipitous explorations. Tentative experiments and rapidly testing approaches that might not work out are all part of the process for getting to the good stuff, and there is no magic bullet to turn data exploration into a simple, linear progression.
That being said, once started it is not a process that lends itself to thinking carefully about the structure of your code or project layout, so it's best to start with a clean, logical structure and stick to it throughout. We think it's a pretty big win all around to use a fairly standardized setup like this one."
"Despite their conceptual simplicity, A/B tests are complex to implement, and flawed setups can lead to incorrect conclusions. One problem that can arise in misconfigured experiments is imbalance, where the groups being compared consist of such dissimilar user populations that any attempt to credit the feature under test with a change in success metrics becomes questionable."
And finally a few thought provoking posts on visualisation:
"My colleagues Ian Johnson, Mike Freeman, and I recently collaborated on a series of data-driven stories about electricity usage in Texas and California to illustrate best practices of Analyzing Time Series Data. We found ourselves repeatedly changing how we visualized the data to reveal the underlying signals, rather than treating those signals as noise by following the standard practice of aggregating the hourly data to days, weeks, or months. Behind many of the best practices we recommended for time series analysis was a deeper theme: actually embracing the complexity of the data."
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink!
"Why is this viewpoint useful? Because it gives us some hints on why ML works or doesn’t work:
1) ML models don’t just minimize a singular loss functions. Instead, they evolve dynamically. We need to consider the dynamical evolution when thinking about ML.
2) We cannot really understand ML models using just a handle of metrics. They capture the macroscopic but not the microscopic behaviors of the model. We should think of metrics as tiny windows into a complex dynamical system, with each metric highlighting just one aspect of our models."
"The benefits of human-like artificial intelligence (HLAI) include soaring productivity, increased leisure, and perhaps most profoundly a better understanding of our own minds. But not all types of AI are human-like–in fact, many of the most powerful systems are very different from humans–and an excessive focus on developing and deploying HLAI can lead us into a trap."
"Suppose you’re a robot visiting a carnival, and you confront a fun-house mirror; bereft of common sense, you might wonder if your body has suddenly changed. On the way home, you see that a fire hydrant has erupted, showering the road; you can’t determine if it’s safe to drive through the spray. You park outside a drugstore, and a man on the sidewalk screams for help, bleeding profusely. Are you allowed to grab bandages from the store without waiting in line to pay? "
"Very rarely does one actually know the data generating function, or even a reasonable proxy - real world data is disorganized, inconsistent, and unpredictable. As a result, the term “distribution” is vague enough to not address the additional specificity necessary to direct actions and interventions"
"Machine learning and traditional algorithms are two substantially different ways of computing, and algorithms with predictions is a way to bridge the two."
"The "adjacent possible" is an idea that comes from Stewart Kaufmann and describes how evolutionary systems grow - at any given point you’ve got the set of things that already exist, and the adjacent possible is the set of things that could exist as the next generation from the current possibilities."
Fun Practical Projects and Learning Opportunities A few fun practical projects and topics to keep you occupied/distracted:
Test your knowledge of all things AI and Stats with the this Quiz from UKRI CDT in Foundational AI
However, no-one told the virus. The latest results from the ONS tracking study estimate 1 in 25 people in England have Covid. This is at least moving in the right direction compared to couple of weeks ago, when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
Simple but elegant diagram showing how a new variant may appear milder even with no change in the underlying virulence due to re-infection
A sketch to explain how a new variant may appear milder even with no change in underlying virulence. This can occur because, when calculating the fraction of cases that are severe, the denominator now includes many re-infections that had previously been averted. A thread. 1/8 pic.twitter.com/XxrYHnb6XY
One of the challenges throughout the pandemic has been understanding and quantifying the relative risk of Covid to other dangerous things. Useful analysis reported in the NY Times
"For example, she estimated that the average vaccinated and boosted person who was at least 65 years old had a risk of dying after a Covid infection slightly higher than the risk of dying during a year of military service in Afghanistan in 2011"
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organisation in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.
James Lupino is pleased to announce that RISC AI and IntelliProp have entered into an agreement to cooperate in the in the development of programs, projects and activities related to system integration of processors for Artificial Intelligence (AI) computing in high-speed network fabrics that connect memory, storage and compute resources. More information here. RISC AI do not use gradient descent but a novel method using modal interval arithmetic to guarantee the optimal solution is found in a single run.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
Lloyds Register are looking for a data analyst to work across the Foundation with a broad range of safety data to inform the future direction of challenge areas and provide society with evidence-based information.
Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
The news from Ukraine is truly devastating and brings a huge dose of perspective to our day to day lives in the UK. I know I for one care rather less about fixing my python package dependencies when I see the shocking scenes from Mariupol… However, those of us more distant from the war do at least have the option to think about other things, and hopefully the data science reading materials below might distract a little…
Following is the April edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We have all been shocked and saddened by events in the Ukraine and our thoughts and best wishes go out to everyone affected
The committee is busy planning out our activities for the year with lots of exciting events and even hopefully some in-person socialising… Watch this space for upcoming announcements.
Louisa Nolan (Chief Data Scientist, Data Science Campus, ONS) is helping drive the Government Data Science Festival 2022, a virtual event running from 27 April to 11 May 2022. This exciting event is a space for the government and UK public sector data science community, and colleagues in the academic sector, to come together to learn, discover, share and connect. This year’s theme is: The Future of Data Science for Public Good. Register here!
Anyone interested in presenting their latest developments and research at the Royal Statistical Society Conference? The organisers of this year’s event – which will take place in Aberdeen from 12-15 September – are calling for submissions for 20-minute and rapid-fire 5-minute talks to include on the programme. Submissions are welcome on any topic related to data science and statistics. Full details can be found here. The deadline for submissions is 5 April.
Janet Bastiman (Chief Data Scientist at NapierAI) recorded a podcast with Moodys on “AI and transparent boxes”, looking at the use of AI in detecting financial crime and explainability- will post the link once it is published.
As we highlight in the Members and Contributors section, Martin was interviewed by the American Statistical Association (ASA) about Practical Data Science & The UK’s AI Roadmap
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
"The notion of a killer robot—where you have artificial intelligence fused with weapons—that technology is here, and it's being used,” says Zachary Kallenborn, a research affiliate with the National Consortium for the Study of Terrorism and Responses to Terrorism (START).
That short-lived saga could be the first weaponized use of deepfakes during an armed conflict, although it is unclear who created and distributed the video and with what motive. The way the fakery unraveled so quickly shows how malicious deepfakes can be defeated—at least when conditions are right.
Not all people targeted by deepfakes will be able to react as nimbly as Zelensky—or find their repudiation so widely trusted. “Ukraine was well positioned to do this,” Gregory says. “This is very different from other cases, where even a poorly made deepfake can create uncertainty about authenticity.”
While debates are heating up on AI campaigning, the National Election Commission (NEC) is yet to determine whether it is legitimate or not. "It is difficult to make a finding on whether it is against the laws governing campaigning or not because it is uncertain how the technologies will be used in the campaign," an NEC official said.
A recent ruling from the FTC in the US is demanding that Weight Watchers “destroy the algorithms or AI models it built using personal information collected through its Kurbo healthy eating app from kids as young as 8 without parental permission”. Interesting development, but not entirely sure what it means and how you would implement it- could you simply retrain the model on new data?
It is becoming easier and easier to create AI systems. There are now a number of solutions available that allow anyone to feed in data and generate automated AI models without writing a single line of code. While there are clearly benefits to increasing access, particularly for well defined use-cases…
Just as clickable icons have replaced obscure programming commands on home computers, new no-code platforms replace programming languages with simple and familiar web interfaces. And a wave of start-ups is bringing the power of A.I. to nontechnical people in visual, textual and audio domains.
“If you’re using low-code, no-code, you don’t really have a good sense of the quality of the ingredients coming in, and you don’t have a sense of the quality of the output either,” he said. While low- and no-code software have value for use in training or experimentation, “I just wouldn’t apply it in subject areas where the accuracy is paramount”.
We have looked into recommendation systems in the past, and how more ‘provocative’ information tends to spread more widely than more mundane (but accurate) news (interesting take on TikTok and the Ukraine War here) – new research using data from Weibo in China gives more insight.
Surprisingly, we find that anger travels easily along weaker ties than joy, meaning that it can infiltrate different communities and break free of local traps because strangers share such content more often
When AI gets attention for recovering lost works of art, it makes the technology sound a lot less scary than when it garners headlines for creating deep fakes that falsify politicians’ speech or for using facial recognition for authoritarian surveillance.
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
"I have rarely been as enthusiastic about a new research direction. We call them GFlowNets, for Generative Flow Networks. They live somewhere at the intersection of reinforcement learning, deep generative models and energy-based probabilistic modelling"
"µP provides an impressive step toward removing some of the black magic from scaling up neural networks. It also provides a theoretically backed explanation of some tricks used by past work, like the T5 model. I believe both practitioners and researchers alike will find this work valuable."
Ai Explainability continues to be a hot research topic. Most widely used approaches attempt to ‘explain’ a given AI output by approximating the local decision criteria. ‘CX-TOM‘ looks to be an interesting new approach in which it “generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user”
Reading and being aware of the evolution and new insights in neuroscience not only will allow you to be a better “Artificial Intelligence” guy 😎, but also a finer neural network architectures creator 👩💻!
Comprehending images and videos is something we all take for granted as humans. However it is an incredible complex task for AI systems, and although we have got a lot better in recent years, even the best systems can still be easily led astray. So research continues, particularly in understanding actions and processes:
Even with the breakthroughs of GPT-3 and other large language models, comprehension and trust (almost “common sense”) are still huge challenges in natural language processing as well. Researchers at DeepMind have released GopherCite which adds a bit more “sense” to the responses given to factual questions (great quote below… emphasis mine!)
“Recent large language models often answer factual questions correctly. But users can't trust any given claim a model makes without fact-checking, because language models can hallucinate convincing nonsense. In this work we use reinforcement learning from human preferences (RLHP) to train "open-book" QA models that generate answers whilst also citing specific evidence for their claims, which aids in the appraisal of correctness"
The standard model for sequential decision-making under uncertainty is the Markov decision process (MDP). It assumes that actions are under control of the agent, whereas outcomes produced by the environment are random ... This, famously, leads to deterministic policies which are brittle — they “put all eggs in one basket”. If we use such a policy in a situation where the transition dynamics or the rewards are different from the training environment, it will often generalise poorly.
We want to train a policy that works well, even in the worst-case given our uncertainty. To achieve this, we model the environment to not be simply random, but being (partly) controlled by an adversary that tries to anticipate our agent’s behaviour and pick the worst-case outcomes accordingly.
Finally another take on assessing generalisation which I think could be groundbreaking: “Assessing Generalization of SGD via Disagreement“, from researchers at Carnegie Mellon University, which allows you assess generalised errors using unlabelled data only!
Stochastic gradient descent (SGD) is perhaps the most popular optimization algorithm for deep neural networks. Due to the non-convex nature of the deep neural network’s optimization landscape, different runs of SGD will find different solutions. As a result, if the solutions are not perfect, they will disagree with each other on some of the unseen data. This disagreement can be harnessed to estimate generalization error without labels:
1) Given a model, run SGD with the same hyperparameters but different random seeds on the training data to get two different solutions.
2) Measure how often the networks’ predictions disagree on a new unlabeled test dataset.
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
AI approaches continue to break new ground in medicine and healthcare:
This analysis showed that different parts of the brain work together in surprising ways that differ from current neuroscientific wisdom. In particular, the study calls into question our current understanding of how brains process emotion
Differing takes on using AI/optimisation techniques to improve healthcare access and costs in the US:
Casinos attempting to help stop gambling addiction with AI.. Good balanced article from the NYTimes highlighting the potential but also the conflict of interest between gambler and casino
“Some operators have more robust responsible gambling programs than others,” says Lia Nower, director of the Center for Gambling Studies at Rutgers University. “But in the end there is a profit motive and I have yet to see an operator in the U.S. put the same amount of money and effort into developing a system for identifying and assisting at-risk players as they do developing A.I. technologies for marketing or extending credit to encourage players to return.”
Nowcasting is useful concept in the modern world – how can make the most of whatever information is currently available to understand the state of the world now or in the near future. Good progress in near-time precipitation forecasting. (“Alexa, should I bring an umbrella?” … “I don’t know, let me check my DGMR PySteps model”…)
Lots going on in the world on NLP and language applications … starting with Facebook/Meta who are doubling down on creating a “universal speech translator“. Love the understated sub-title: “Universal AI translation could be a killer app for Meta’s future“…
Google is now automating document summarisation within Google Docs …. which may put a few “cliff notes” companies out of business… Again, Google are very impressive at taking cutting edge research (large pre-trained language models for both natural language understanding and natural language understanding) and embedding it in practical tools available to anyone
Perhaps as a counterpoint to the slightly grumpy art-historian we mentioned in the section above, DeepMind is using its formidable capabilities to help historians better interpret ancient inscriptions– not just translating, but attribution both chronologically and geographically.
Instead of relying on expert opinion, the computer scientists used a mathematical approach known as stylometry. Practitioners say they have replaced the art of the older studies with a new form of science, yielding results that are measurable, consistent and replicable.
Finally, taking the ‘auto-coders’ out for a spin…
Writing games with ‘no-code’ (including a minimal ‘Legend of Zelda’) using OpenAI’s code-davinci codex model. “There are limitations, and coding purely by simple text instructions can stretch your imagination, but it’s a huge leap forward and a fun experiment”
And now that ‘Copilot’ (powered by OpenAI codex) has been in the wild for a little while, we are starting to see interesting use cases and commentary
"I too was pretty skeptical of Copilot when I started using it last summer.
However it is shockingly good for filling out Python snippets - ie smarter autocomplete when teaching.
Popular libraries like Pandas, Beautiful Soup, Flask are perfect for this.
About 80% time it will fill out the code exactly they way I would want. About 10% time it will be something you want to correct or nudge.
Then about 10% of time it will be a howler or anti-pattern."
How does that work? A new section on understanding different approaches and techniques
I still struggle with the basic 4 dimensions of our physical world. When I first heard about 768-dimension embeddings, I feared my brain would escape from my ear. If you can relate, if you want to truly master the tricky subject of NLP encoding, this article is for you.
Surprisingly few software engineers and scientists seem to know about it, and that makes me sad because it is such a general and powerful tool for combining information in the presence of uncertainty. At times its ability to extract accurate information seems almost magical— and if it sounds like I’m talking this up too much, then take a look at this previously posted video where I demonstrate a Kalman filter figuring out the orientation of a free-floating body by looking at its velocity. Totally neat!
One thing we all do on a regular basis is load up some data and then try and get a feel for it- how big, how many dimensions, what are the characteristics of and relationships between the dimensions etc etc. I normally just plug away in pandas, but there are now various elegant ‘profiling’ packages that do a lot of the work for you, well worth exploring:
If you are investigating Deep Learning, it is increasingly likely you will be using PyTorch. This looks like a very useful add on for recommenders (TorchRec), and this ‘NN template‘ could be useful in setting up your PyTorch projects.
Finally, an excellent review of ML Competitions over the last year across Kaggle and other platforms from newsletter subscribers Harald Carlens and Eniola Olaleye (shorter version here) – lots of great insight into the libraries and approaches used.
Practical tips How to drive analytics and ML into production
“In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.”
Ok… so you have your team setup, how should you run it? What principals should you adhere to? Great suggestions here (“0/1/Done Strategy”) from newsletter subscriber Marios Perrakis
When you have models, pipelines and decision tools in production, being used across the organisation, you need to know they are working… or at least know when something has gone wrong. That is where ‘observability’ comes in – incredibly useful if you can get it right.
Part of observability is understanding why something has changed. This is well worth a read- are there ways you can automatically explain changes in aggregations through ‘data-diff algorithms‘?
We talk about MLOps on a reasonably regular basis – how best to implement, manage and monitor your machine learning models in production. Still struggling to figure out the right approach? You are definitely no the only one – “MLOps is a mess“
MLOps is in a wild state today with the tooling landscape offering more rare breeds than an Amazonian rainforest.
To give an example, most practitioners would agree that monitoring your machine learning models in production is a crucial part of maintaining a robust, performant architecture.
However when you get around to picking a provider I can name 6 different options without even trying: Fiddler, Arize, Evidently, Whylabs, Gantry, Arthur, etc. And we haven’t even mentioned the pure data monitoring tools.
Bigger picture ideas Longer thought provoking reads – musing from some of the ‘OGs’ this month! – lean back and pour a drink!
Whether or not AI systems are or ever can be truly ‘intelligent’, whether they really comprehend, even whether they have consciousness are very contentious questions… Mike Loukides kicks things off by digging into what we really mean by “understands”
"Comprehension is a poorly-defined term, like many terms that frequently show up in discussions of artificial intelligence: intelligence, consciousness, personhood. Engineers and scientists tend to be uncomfortable with poorly-defined, ambiguous terms. Humanists are not. My first suggestion is that these terms are important precisely because they’re poorly defined, and that precise definitions (like the operational definition with which I started) neuters them, makes them useless. And that’s perhaps where we should start a better definition of comprehension: as the ability to respond to a text or utterance."
Nope. Not even for true for small values of "slightly conscious" and large values of "large neural nets". I think you would need a particular kind of macro-architecture that none of the current networks possess.
But the most important trend I want to comment on is that the whole setting of training a neural network from scratch on some target task (like digit recognition) is quickly becoming outdated due to finetuning, especially with the emergence of foundation models like GPT. These foundation models are trained by only a few institutions with substantial computing resources, and most applications are achieved via lightweight finetuning of part of the network, prompt engineering, or an optional step of data or model distillation into smaller, special-purpose inference networks
And finally, a bit more esoteric … “musings on typicality” – worth a read and a cold cloth to the head!
To summarise: suppose you have an unfair coin that lands on heads 3 times out of 4. If you toss this coin 16 times, you would expect to see 12 heads (H) and 4 tails (T) on average. Of course you wouldn’t expect to see exactly 12 heads and 4 tails every time: there’s a pretty good chance you’d see 13 heads and 3 tails, or 11 heads and 5 tails. Seeing 16 heads and no tails would be quite surprising, but it’s not implausible: in fact, it will happen about 1% of the time. Seeing all tails seems like it would be a miracle. Nevertheless, each coin toss is independent, so even this has a non-zero probability of being observed.
If we do not ignore the order, and ask which sequence is the most likely, the answer is ‘all heads’. That may seem surprising at first, because seeing only heads is a relatively rare occurrence. But note that we’re asking a different question here, about the ordered sequences themselves, rather than about their statistics
Fun Practical Projects and Learning Opportunities A few fun practical projects and topics to keep you occupied/distracted:
I really like this – “If machine learning were around in the 1600s, would Newton have discovered his law of gravitation?” – Brilliant
What happens when you don’t have the data? Most of the decisions we have to make on a day to day basis are done under uncertainty – how do we get better at dealing with this uncertainty and make better decisions? Practice – checkout Metaculus for a wide range of topical predictions you can get stuck into (hat-tip Ian Ozsvald)
"3. Treat research hypotheses like impressionist paintings
The big picture looks coherent but the details wash out when scrutinized. Use vague sciency sounding concepts that can mean anything.
Don't show it to the statistician until the end of the study. its best as a surprise"
However, no-one told the virus. The latest results from the ONS tracking study estimate 1 in 16 people (over 6%) in England have Covid. It’s worse in Scotland where the figure is 1 in 11. This is as bad as it has ever been in the whole 2+ years of the pandemic and a far cry from the 1 in 1000 we had last summer. Bear in mind in the chart below that the levels we had in February 2021 were enough to drive a national lockdown …
The RSS is running a series of ‘Covid Evidence Sessions’ to highlight important statistical and data issues that the upcoming public inquiries should look into.
Updates from Members and Contributors
As highlighted in the practical tips section, Harald Carlens and Eniola Olaleye have finished their annual review of ML Competitions across Kaggle and other platforms, and written an excellent summary here (shorter version here)
Also as highlighted above, Marios Perrakis recently published an article on implementing a novel operational strategy to delivering applied Data Science: “0/1/Done strategy” for Data Science
Sarah Phelps is helping organise the first of this year’s ONS – UNECE Machine Learning Groups Coffee and Coding sessions, on 27 April 2022 at 0900 – 1100 and repeated at 1430 – 1630. This will be an interactive introductory session that discusses machine learning foundations and focuses on the theory behind these techniques. (Free registration using the links provided)
Kevin O‘Brien calls our attention to the excellent PyDataGlobal organisation, and their upcoming PyData London conference (Fri 17th – Sun 19th June at the Tower Hotel, London). Still opportunities to present your work- if you are interested, submit here
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
Lloyds Register are looking for a data analyst to work across the Foundation with a broad range of safety data to inform the future direction of challenge areas and provide society with evidence-based information.
Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Another month flies by – at least it finally seems to be getting a bit lighter in the mornings although I fear sunny spring days are still a way off… I imagine you are suffering withdrawal from a lack of dramatic Olympics Curling action so perhaps some thought provoking data science reading materials to fill the void…
Following is the March edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We have all been shocked and saddened by events in the Ukraine and our thoughts and best wishes go out to everyone affected
The committee is busy planning out our activities for the year with lots of exciting events and even hopefully some in-person socialising… Watch this space for upcoming announcements.
We are very pleased to announce that Jennifer Hall, Senior AI Lab Data Scientist at NHSX and Will Browne, Associate Partner – Data Science & Analytics at CF Healthcare are both joining the Data Science and AI Section committee. They bring a wealth of talent and experience in all aspects of data science and we are very much looking forward to their contributions across our various activities.
Anyone interested in presenting their latest developments and research at the Royal Statistical Society Conference? The organisers of this year’s event – which will take place in Aberdeen from 12-15 September – are calling for submissions for 20-minute and rapid-fire 5-minute talks to include on the programme. Submissions are welcome on any topic related to data science and statistics. Full details can be found here. The deadline for submissions is 5 April.
The Royal Statistical Society (RSS) is developing resources to support everyone working in data science to meet their learning and development goals and career objectives. If you have an interest in data science, we invite you to take part in this survey, whether or not you are a member of RSS.
The survey should take around 15 minutes to complete. Your responses will be invaluable in helping us to understand and meet the wants and needs of the data science community, and to support your work in this exciting, fast-developing field.
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
"The UK Statistics Authority have written to Downing St to advise them that the Prime Minister's claim that there are more people in work now than at the start of the pandemic is wrong. He has now made this claim 7 times but knows it is wrong! When will he correct the record?!."
Sadly the level of statistical literacy across UK politicians is not good, as recent RSS research has shown
"Those surveyed were asked: suppose there was a diagnostic test for a virus. The false-positive rate (the proportion of people without the virus who get a positive result) is one in 1,000. You have taken the test and tested positive. What is the probability that you have the virus? Of the politicians surveyed, 16 per cent gave the correct answer that there was not enough information to know."
Of course understanding official statistics is often not straightforward. It looks like the official ONS Excess Mortality figures will start to include 2021 figures into their baseline and so potentially look better than they are compared to the long run average.
The truth is AI failures are not a matter of if but when. AI is a human endeavor that combines information about people and the physical world into mathematical constructs. Such technologies typically rely on statistical methods, with the possibility for errors throughout an AI system’s lifespan. As AI systems become more widely used across domains, especially in high-stakes scenarios where people’s safety and wellbeing can be affected, a critical question must be addressed: how trustworthy are AI systems, and how much and when should people trust AI?
An extended piece in on the ‘duty of care’ the leading AI developers have with discussion from Safiya Umoja Noble (MacArthur Genius Fellowship recipient and an Associate Professor of Gender Studies and African American Studies at UCLA) and Meredith Whittaker (Faculty Director and cofounder of the AI Now Institute)
We found two key through lines: Lawmakers and the public lack fundamental access to information about what algorithms their agencies are using, how they’re designed, and how significantly they influence decisions.
Tesla Chief Executive Officer Elon Musk said on Twitter "there were no safety issues" with the function. "The car simply slowed to ~2 mph & continued forward if clear view with no cars or pedestrians," Musk wrote.
Concerns over physical job losses to AI are surfacing are surfacing as advances in artificial intelligence and other technology allow machines to be operated from far away
To train InstructGPT, OpenAI hired 40 people to rate GPT-3’s responses to a range of prewritten prompts, such as, “Write a story about a wise frog called Julius” or “Write a creative ad for the following product to run on Facebook.” Responses that they judged to be more in line with the apparent intention of the prompt-writer were scored higher. Responses that contained sexual or violent language, denigrated a specific group of people, expressed an opinion, and so on, were marked down. This feedback was then used as the reward in a reinforcement learning algorithm that trained InstructGPT to match responses to prompts in ways that the judges preferred.
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
Some strong developments in the use of artificially generated faces to help improve facial recognition systems:
They have developed a Natural Language Processing (NLP) approach that does not use text or labels at all – it is able to learn directly from raw audio signals- pretty astonishing!
"GSLM leverages recent breakthroughs in representation learning, allowing it to work directly from only raw audio signals, without any labels or text. It opens the door to a new era of textless NLP applications for potentially every language spoken on Earth—even those without significant text data sets."
Not to be outdone, openAI has published more groundbreaking work:
At face value, solving Maths Olympiad problems might not have ground breaking applications, but when you stop to think about what is going on, it is very impressive
“People can flexibly maneuver objects in their physical surroundings to accomplish various goals. One of the grand challenges in robotics is to successfully train robots to do the same, i.e., to develop a general-purpose robot capable of performing a multitude of tasks based on arbitrary user commands"
Continued progress in making Reinforcement Learning more efficient:
Very cool- Waymo and Google Research working on large scale scene reconstruction from limited inputs (Block-NeRF)
Pre-Training models on comparable readily available data is often a good way of building success when you have limited data sets – but how far can it go? Useful research exploring the limits of pre-training.
“It’s an incredibly powerful method,” says Jonathan Citrin at the Dutch Institute for Fundamental Energy Research, who was not involved in the work. “It’s an important first step in a very exciting direction.”
“Outracing human drivers so skillfully in a head-to-head competition represents a landmark achievement for AI,” said Chris Gerdes, a professor at Stanford who studies autonomous driving, in an article published on Wednesday alongside the Sony research in the journal Nature.
"To help clinicians avoid remedies that may potentially contribute to a patient’s death, researchers at MIT and elsewhere have developed a machine-learning model that could be used to identify treatments that pose a higher risk than other options"
How does that work? A new section on understanding different approaches and techniques
Algorithms can be a somewhat neglected area in a data scientists skill-set, but are very useful, particularly in optimisation work – here is good step by step explanation of the A* Algorithm for graph search
"A* is a modification of Dijkstra’s Algorithm that is optimized for a single destination. Dijkstra’s Algorithm can find paths to all locations; A* finds paths to one location, or the closest of several locations. It prioritizes paths that seem to be leading closer to a goal."
Finally … ever heard of vector databases? me neither, but interesting concept
"Vector databases are purpose-built to store, index, and query across embedding vectors generated by passing unstructured data through machine learning models."
Practical tips How to drive analytics and ML into production
"Professor: “Yes, outstanding. However, you failed to ask me what metrics I used to grade your model. Your opinion of model quality doesn’t matter. It’s your users’ needs that do.”
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink!
"A lot has happened in the past half century! The eight ideas reviewed below represent a categorization based on our experiences and reading of the literature and are not listed in a chronological order or in order of importance. They are separate concepts capturing different useful and general developments in statistics."
There are lots of “here are all the problems with statistical significance” type articles out there, but the visual examples in this one make it more compelling than many
"You can have a miniscule effect size and still have a significant effect. Do we always prefer the (c) to the (a)? Is a meager, but mostly positive benefit necessarily better than a treatment potentially of large benefit to some but harmful to others necessarily? Wouldn’t it be in our interest to understand this spread of outcomes so we could isolate the group of individuals who benefit from the treatment?'”
"So consider this Deep Blue’s final gift, 25 years after its famous match. In his defeat, Kasparov spied the real endgame for AI and humans. “We will increasingly become managers of algorithms,” he told me, “and use them to boost our creative output—our adventuresome souls.”
But in the future, he says, systems will be needed that can handle all other scenarios as well: “It’s not just about the trajectory of a missile or the movement of a robotic arm, which can be modeled through careful mathematics. It’s about everything else, everything we observe in the world: About human behavior, about physical systems that involve collective phenomena like water or branches in a tree, about complex things for which humans can easily develop abstract representations and models,” LeCun said
Bringing data to life – the art and science of visualisation Leland Wilkinson, author of Grammar of Graphics, sadly passed away at the end of last year. Hadley Wickhamcreated ggplot2 as a way to implement the ideas contained in this formative work (gg = grammar of graphics) and I know I for one have been heavily influenced by it in how I think about visualisation. In memory of Leland I thought it would be fitting to call out some recent articles of interest in the field.
"The problem with guidelines based on precision is that visualization is not really about precision. Sure, there are cases where precision matters because it allows readers to detect important differences that would otherwise be missed. But visualization is less about precision, and much more about what the visual representation expresses."
Given the government is removing requirements and incentives to test for Covid, the ONS Coronavirus infection survey is now one of the only ways we can tell the prevalence of the virus in our society.
The latest results estimate 1 in 25 people (4%) in England have Covid. While this is down from its peak of 1 in 15 in January it is still a long way from the 1 in 1000 we had last summer. Bear in mind in the chart below that the levels we had in February 2021 were enough to drive a national lockdown …
All this has led to a great deal of commentary questioning the decision to end all restrictions, from scientists (for example here, here and here) as well as political commentators.
Updates from Members and Contributors
Jona Shehu and her colleagues at Helix Data Innovation are hosting what looks to be a high quality and relevant online roundtable on model explainability with leaders across the AI, finance, consumer rights and data governance sectors. The event is on March 15th (11-12.30) and is free to attend. Register here
Kevin O‘Brien highlights the inaugural SciMLCon (of the Scientific Machine Learning Open Source Software Community) taking place online on Wednesday 23rd March 2022. Core topics include: Physics-Informed Model Discovery and Learning, Compiler-Assisted Model Analysis and Sparsity Acceleration, ML-Assisted Tooling for Model Acceleration and many more. SciMLCon is focused on the development and applications of the Julia-based SciML tooling -with expansion into R and Python planned in the near future.
Maria Rosario Mestre is CEO of DataQA which offers tools to search, label and organise unstructured documents: sounds very useful! They are currently enrolling beta customers for the first release of the platform which includes a free trial so could be well worth checking out.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
Lloyds Register are looking for a data analyst to work across the Foundation with a broad range of safety data to inform the future direction of challenge areas and provide society with evidence-based information.
Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Well, January seemed to flash by in the blink of an eye- certainly the holiday period seems a long time ago already. All is not lost- the Winter Olympics seems to have crept up on us and is just about to start which will no doubt provide some entertainment and distraction…. as I hope will some thought provoking data science reading materials.
Following is the February edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are all conscious that times are incredibly hard for many people and are keen to help however we can- if there is anything we can do to help those who have been laid-off (networking and introductions help, advice on development etc.) don’t hesitate to drop us a line.
The committee is busy planning out our activities for the year with lots of exciting events and even hopefully some in-person socialising… Watch this space for upcoming announcements.
We do in fact have a couple of spaces opening up on our committee (RSS Data Science and AI Section) – if you are interested in learning more please contact James Weatherall
Anyone interested in presenting their latest developments and research at the Royal Statistical Society Conference? The organisers of this year’s event – which will take place in Aberdeen from 12-15 September – are calling for submissions for 20-minute and rapid-fire 5-minute talks to include on the programme. Submissions are welcome on any topic related to data science and statistics. Full details can be found here. The deadline for submissions is 5 April.
Our very own Giles Pavey took part in a panel debate, exploring the role of AI in creating trustworthy digital commerce – see recording here
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
With the anniversary of the January 6th attack on the US Capital, there is commentary in the mainstream press about misinformation and how algorithms can both exacerbate and help curb the problem – see here in the Washington Post for example.
"The provocative idea behind unrest prediction is that by designing an AI model that can quantify variables — a country’s democratic history, democratic “backsliding,” economic swings, “social-trust” levels, transportation disruptions, weather volatility and others — the art of predicting political violence can be more scientific than ever."
Some dry but useful materials published regarding military use of AI:
Ethical Principals for Artificial Intelligence published by the JAIC (part of the US Department of Defence). “DoD personnel will exercise appropriate levels of judgment and care, while remaining responsible for the development, deployment, and use of AI capabilities.” – it’s a start.
We’ve posted previously about bias in recruiting and hiring algorithms – so it’s welcome to see the Data and Trust Alliance‘s publication of their Algorithmic Bias Safeguards for Workforce: criteria and education for HR teams to evaluate vendors on their ability to detect, mitigate, and monitor algorithmic bias in workforce decisions
There was an interesting recent recommendation from the UK Law Commission that users of self driving cars should have immunity from a wide range of motoring offences. This is increasingly relevant, as the various self-driving car providers move towards commercial propositions- Waymo (Google/Alphabet’s self-driving unit), for instance, recently announced its first commercial autonomous trucking customer (interesting background on how Waymo does what it does here)
"While a vehicle is driving itself, we do not think that a human should be required to respond to events in the absence of a transition demand (a requirement for the driver to take control). It is unrealistic to expect someone who is not paying attention to the road to deal with (for example) a tyre blow-out or a closed road sign. Even hearing ambulance sirens will be difficult for those with a hearing impairment or listening to loud music.”
Thought provoking article in Wired about the changing dynamics of inter-personal communication when mediated through “auto suggestions” and other AI driven tools.
"People were more likely to roll with a positive suggestion than a negative one— participants also often found themselves in a situation where they wanted to disagree, but were only offered expressions of agreement. The effect is to make a conversation go faster and more smoothly" ...
... "This technology (combined with our own suggestibility) could discourage us from challenging someone, or disagreeing at all. In making our communication more efficient, AI could also drum our true feelings out of it, reducing exchanges to bouncing “love it!” and “sounds good!” back at each other"
Developments in Data Science… As always, lots of new developments on the research front and plenty of arXiv papers to read…
The research theme around making models more ‘efficient’ (whether that’s in terms of power consumption, model size, data usage etc) continues:
Focusing on reducing computational cost for low power network-edge usage, ‘Mobile-Former‘ breaks all sorts of records
More progress on ‘few-shot learning’ (making accurate predictions with limited examples) – this time with ‘HyperTransformers‘
Active Learning is an elegant approach to improving sample efficiency by focusing efforts in the most productive areas of the data space – however, watch out for outliers
Then some more random research directions…
An exploration of ‘Prospective Learning’ (as opposed to retrospective learning, ie learning from past experience) – how do you ‘learn’ a new object and put it in the right context?
The AI Economist… optimal economic policy with two-level Deep Reinforcement Learning!
Automated model search and training (or AutoML) has become relatively commonplace and accessible in supervised learning tasks – could it work in Reinforcement Learning? Yes, but it’s hard – AutoRL
“However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go.”
"Over the last several decades, I've witnessed a lot of change in the fields of machine learning (ML) and computer science. Early approaches, which often fell short, eventually gave rise to modern approaches that have been very successful. Following that long-arc pattern of progress, I think we'll see a number of exciting advances over the next several years, advances that will ultimately benefit the lives of billions of people with greater impact than ever before"
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
What seems like our now monthly update from ETH Zürich’s Robotic Systems Lab this time ‘robots learning to hike‘ (cue robot-dog interaction videos…).
In order for robots to take action, they have to understand the world around them, a far from trivial task: a couple of useful developments in this space using large language models to understand the relationship between objects and relevant actions, from MIT and also from Carnegie-Mellon/ Google Brain
“In an effort to solve this problem, MIT researchers have developed a model that understands the underlying relationships between objects in a scene. Their model represents individual relationships one at a time, then combines these representations to describe the overall scene. This enables the model to generate more accurate images from text descriptions, even when the scene includes several objects that are arranged in different relationships with one another.”
“It's a monumental shift,” says Jahmy Hindman, Deere’s chief technology officer, of the new machine, revealed at the 2022 Consumer Electronics Show in Las Vegas. “I think it's every bit as big as the transition from horse to tractor.”
"'Is it safe to walk downstairs backwards if I close my eyes?'
GPT-3: Yes, there is nothing to worry about. It’s safe because the spiral stairs curve outwards, it will make your descent uncomfortable.
I asked the same question three more times and got three authoritative, confusing, and contradictory answers:
GPT-3: That depends. Do you have a TV?
GPT-3: No, it is not safe.
GPT-3: Yes, it is safe to walk downstairs backwards if you close your eyes."
Great in-depth article on how ‘AI conquered poker’ (I guess solvers are officially ‘AI’ now…)
“You’re playing a pot that’s effectively worth half a million dollars in real money,” he said afterward. “It’s just so much goddamned stress.”
Amazon is increasingly good at getting AI into production in real world situations, focusing on the outcomes not necessarily the underlying research or approach.
How does that work? A new section on understanding different approaches and techniques
For those with a programming background, vectorisation may come naturally, but it can be hard to think through if you are new to it … it does speed things up though, so worth digging into: good python tutorial here.
JAX is a relatively new but very scalable framework for numerical methods (bayesian sampling etc) developed at DeepMind – definitely worth exploring
It’s always good to understand at a low level how different modelling approaches work. If you’re unclear on the fundamentals of neural networks, this is an excellent introductory guide from Simon Hørup Eskildsen (love that it’s called ‘Napkin Math’!)
"In this edition of Napkin Math, we'll invoke the spirit of the Napkin Math series to establish a mental model for how a neural network works by building one from scratch"
I know, we’ve had a fair few ‘this is how Transformers work’ posts over the last few months… but they are so central to many of the image processing and NLP improvements over the last few years that checking out another good one couldn’t hurt..
"It was in the year 2017, the NLP made the key breakthrough. Google released a research paper “Attention is All you need” which introduced a concept called Attention. Attention helps us to focus only on the required features instead of focusing on all features. Attention mechanism led to the development of the Transformer and Transformer-based models.."
Finally, variational autoencoders... unsupervised learning is an area of data science that can sometimes feel neglected, and variational autoencoders are a fantastic tool in the unsupervised learning arsenal, leveraging the power of Deep Learning.
For anyone interested in learning more about how DeepMind does what it does, I definitely recommend Hannah Fry‘s podcast- the last episode, ‘A breakthrough unfolds‘ tells the story well of how they went from winning at Go to predicting protein structures…
Practical tips How to drive analytics and ML into production
More commentary on why a data driven (rather than model driven) approach to ML problems often leads to better outcomes … the Andrew Ng philosophy!
“Real-Time” machine learning means different things to different people- useful post talking through the definitions, challenges and some options for solving them in production from Chip Huyen
Not sure about this one- ‘Offline Replay Experimentation‘. It sounds incredibly useful (running the equivalent of AB tests on offline data) but I need to dig more into how it works…
Another useful tutorial on approaches to testing for ML models … to stop data drift before it occurs!
Managing models and experiments is a whole can of worms on it’s own… so when DeepMind releases their framework for managing model experiments (xmanager) it’s worth playing around with!
Ian Ozsvald (pyData London founder) writes an excellent newsletter on all things python which is well worth subscribing to. Recent updates include commentary on Kubernetes and TDD/linting.
Finally a few ‘life as a data scientist’ tips and tricks:
And finishing with a thoughtful review on the first year of being a data science manager.
"I’m not a management expert, but I did try really hard during my first year managing and I’ve since spent time digesting the experience. My hope is that others will find a few of the things I learned useful when they’re at the start of their own management journey.”
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink!
"Isaac Newton apocryphally discovered his second law – the one about gravity – after an apple fell on his head. Much experimentation and data analysis later, he realised there was a fundamental relationship between force, mass and acceleration. He formulated a theory to describe that relationship – one that could be expressed as an equation, F=ma – and used it to predict the behaviour of objects other than apples. His predictions turned out to be right (if not always precise enough for those who came later).
Contrast how science is increasingly done today."
Two interesting articles on what it means to ‘understand’ and whether or not our current versions AI truly do so:
"These schemas were the subject of a competition held in 2016 in which the winning program was correct on only 58% of the sentences — hardly a better result than if it had guessed. Oren Etzioni, a leading AI researcher, quipped, 'When AI can’t determine what ‘it’ refers to in a sentence, it’s hard to believe that it will take over the world.'”
Lex chatting with Yann Lecun – has to be worth a listen even if only to figure out what he means by ‘dark matter of intelligence’
"Repeatedly tap on a box of marbles or sand and the pieces will pack themselves more tightly with each tap. However, the contents will only approach its maximum density after a long time and if you use a carefully crafted tapping sequence. But in new experiments with a cylinder full of dice vigorously twisted back and forth, the pieces achieved their maximum density quickly. The experiments could point to new methods to produce dense and technologically useful granular systems, even in the zero gravity environments of space missions."
Practical Projects and Learning Opportunities As always here are a few potential practical projects to keep you busy:
Fancy contributing to an open source project- useful thread on reddit highlighting a few candidates
Although there are still some Covid restrictions in place, the UK Government has eased a number of rules: to be fair, it’s quite hard to keep track. Omicron is far from gone though…
Last month, we called the ONS Coronavirus infection survey‘s estimate of 1 in 25 people with Covid in England, “astonishing”, given that it was 1 in 1000 back in May. Well, as the government eases restrictions, the latest ONS Coronavirus infection survey estimates 1 in 20 people in England have Covid. I guess it’s still astonishing…
Kevin O‘Brien highlights a couple of excellent events:
The inaugural SciMLCon (of the Scientific Machine Learning Open Source Software Community) will take place online on Wednesday 23rd March 2022. SciMLCon is focused on the development and applications of the Julia-based SciML tooling -with expansion into R and Python planned in the near future.
JuliaCon which will be free and virtual with the main conference taking place Wednesday 27th July to Friday 29th July 2022. (Julia is a high performance, high-level dynamic language designed to address the requirements of high-level numerical and scientific computing, and is becoming increasingly popular in Machine Learning, IOT, Robotics, Energy Trading and Data Science)
Harald Carlens launched a very useful Discord server to help facilitate easier matchmaking for teams in the competitive ML community spanning across Kaggle and other platforms (AIcrowd/Zindi/DrivenData/etc), to go along with the mlcontests.com website. There are over 250 people on the server already and the audience is growing daily. More info here
Sarah Parker calls out the work of Professor Simon Maskell, (Professor Autonomous Systems, and Director of the EPSRC Centre for Doctoral Training in Distributed Algorithms at University of Liverpool), who has developed a Bayesian model used by the UK Government to estimate the UK’s R number – the reproduction number – of COVID -19. More info here.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
Cazoo is looking for an experienced Principal Data Scientist to lead technical development of a wide range of ML projects – more details here (I’m biased… but this is an amazing job for the right person 😉 )
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Happy New Year! I hope you all had as relaxing a holiday period as possible and enjoyed the fireworks from around the world… London trumps them all as far as I’m concerned although I’m clearly biased. As we all gear up for 2022, perhaps time for some thought provoking data science reading materials to help guide plans for the year ahead.
Following is the January edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are all conscious that times are incredibly hard for many people and are keen to help however we can- if there is anything we can do to help those who have been laid-off (networking and introductions help, advice on development etc.) don’t hesitate to drop us a line.
2021 has been a busy and productive year for the RSS Data Science and AI section, focusing on our goals of:
Supporting the career development of data scientists and AI specialists
Fostering good practice for professional data scientists
Providing the voice of the practitioner to policy-makers
A few edited highlights:
We kicked off our “Fireside Chat” series back in February with an amazing discussion with Andrew Ng attended by over 500 people, followed up with a similarly thought provoking conversation with Anthony Goldblum, founder of Kaggle, in May.
In March we hosted our inaugural Data Science Ethics Happy Hour, discussing a wide range of topics focused on ethical challenges with an experienced panel. We also hosted “Confessions of a Data Scientist” at the annual RSS conference based on contributions from you, our experienced data science practitioner readership.
Throughout the year we have engaged with various initiatives focused on the accreditation of data science. More recently we have been actively engaged in the UK Government’s AI Roadmap and strategy, first conducting a survey and publishing our findings and critiques (which were publicly acknowledged). We then hosted a well attended event focused on the implications of the strategy and will be collaborating with the UK Government’s Office for AI to host a roundtable event on AI Governance and Regulation, on of the 3 main pillars of the UK AI Strategy.
… And we’ve managed to produce 12 monthly newsletters, expanding our readership
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
It’s not exactly breaking news that the ImageNet data set is very influential in driving image recognition AI research, but new research from the University of California and Google Research highlights the overall importance of these ‘benchmark’ datasets, largely from influential western institutions, and frequently from government organisations.
"[We] find that there is increasing inequality in dataset usage globally, and that more than 50% of all dataset usages in our sample of 43,140 corresponded to datasets introduced by twelve elite, primarily Western, institutions."
We know that Governments are far from perfect and evidence from around the world continues to come in, this time from South Korea where 170m facial images obtained in the immigration process were passed on to private AI developers.
TikTok is considered by many to have one of the best recommendation systems, driving phenomenal usage figures amongst its users. The NYTimes obtained an internal company document that offers a new level of detail about how the algorithm works. It’s clear that the algorithm optimises for retention and time-spent much like many other similar systems.
"The company’s edge comes from combining machine learning with fantastic volumes of data, highly engaged users, and a setting where users are amenable to consuming algorithmically recommended content (think how few other settings have all of these characteristics!). Not some algorithmic magic.”
So TikTok is not doing anything inherently different to facebook, twitter and any other site that recommends content. And in this excellent in-depth article, MIT Technology Review walks through how ‘clickbait farms‘ use these sites to spread misinformation.
On an average day, a financially motivated clickbait site might be populated with celebrity news, cute animals, or highly emotional stories—all reliable drivers of traffic. Then, when political turmoil strikes, they drift toward hyperpartisan news, misinformation, and outrage bait because it gets more engagement”
To try and combat this, HalloApp (founded by Neeraj Arora and Michael Donohue, who helped build WhatsApp) is building an algorithmic feed engine that is less prone to these influences- useful commentary here
"It’s not the most “interesting” stories that make their way to the top of your News Feed (the word “interesting” implying “valuable”), but the most emotional. The most divisive. The ones with the most Likes, Comments, and Shares, and most likely to spark debate, conflict, anger. Either that, or the content a brand was willing to spend the most money sponsoring—all of which reveals a disconcerting conclusion: as a user of these platforms, being forced to see what the algorithm and brands want you to see, you have no rights"
The Stanford University Human Centred AI group has published “A New Direction for Machine Learning in Criminal Law” proposing the use of ML to analyse decision making in the criminal legal system not to predict human behaviour but to better understand the factors that led to past decisions.
Developments in Data Science… As always, lots of new developments…
Not surprisingly given the date, there have been a number of reviews of the year in data science, AI, and ML research in 2021- here are some of the best:
“It feels like Galileo picking up a telescope and being able to gaze deep into the universe of data and see things never detected before.”
In addition, DeepMind released Gopher, a new 280 billion parameter model, together with insight into the areas where parameter scaling helps, and where it is less important
"Our research investigated the strengths and weaknesses of those different-sized models, highlighting areas where increasing the scale of a model continues to boost performance – for example, in areas like reading comprehension, fact-checking, and the identification of toxic language. We also surface results where model scale does not significantly improve results — for instance, in logical reasoning and common-sense task"
"The performance of supervised learning tasks improves with more high-quality labels available. However, it is expensive to collect a large number of labeled samples. There are several paradigms in machine learning to deal with the scenario when the labels are scarce. Semi-supervised learning is one candidate, utilizing a large amount of unlabeled data conjunction with a small amount of labeled data"
Given the increasing prevalence of PyTorch this looks very useful – miniTorch
MiniTorch is a diy teaching library for machine learning engineers who wish to learn about the internal concepts underlying deep learning systems. It is a pure Python re-implementation of the Torch API designed to be simple, easy-to-read, tested, and incremental. The final library can run Torch code. The project was developed for the course 'Machine Learning Engineering' at Cornell Tech.
Practical tips How to drive analytics and ML into production
Some excellent commentary from Rachel Thomas at Fast.AI on how to avoid “Data Disasters”, highlighting the importance of “data work” – including a case study on the UK Covid Tracking App!
In a similar vein, new research accentuates how critical relevant data sets are to ML model success, “99% of computer vision (CV) teams have had a machine learning (ML) project canceled due to insufficient training data”
"We think about three large primitives: the ingest primitive in this chat interface, the transform interface, and the publisher interface. All of these apply to “data sets” – which could be tables, they could be models, they could be reports, dashboards, and all the other things that you mentioned. When you think of ingest, transform, publish, these are all operating on instead of storage. We are building the lakehouse architecture: our storage is GCS, Iceberg table format, plus Parquet. … Trino is our query engine.”
Bigger picture ideas Longer thought provoking reads – lean back and pour a drink!
"Well, computers haven’t changed much in 40 or 50 years. They’re smaller and faster, but they’re still boxes with processors that run instructions from humans. AI changes that on at least three fronts: how computers are made, how they’re programmed, and how they’re used. Ultimately, it will change what they are for.
The core of computing is changing from number-crunching to decision-making."
"This post argues that we should develop tools that will allow us to build pre-trained models in the same way that we build open-source software. Specifically, models should be developed by a large community of stakeholders who continually update and improve them. Realizing this goal will require porting many ideas from open-source software development to building and training models, which motivates many threads of interesting research."
"In this series, I focus on the third trend [novel computing infrastructure capable of processing large amounts of data at massive scales and/or with fast turnaround times], and specifically, I will give a high-level overview of accelerators for artificial intelligence applications — what they are, and how they became so popular."
Practical Projects and Learning Opportunities As always here are a few potential practical projects to keep you busy:
As we head into a new year, there are some depressing similarities with last year. The new Omicron cases to skyrocket world wide, with the UK being at the forefront…Thank goodness for vaccinations
The latest ONS Coronavirus infection survey estimates the current prevalence of Covid in the community in England to be an astonishing 1 in 25 people, by far the largest prevalence we have seen (over 2m people currently with coronavirus)… Back in May the prevalence was less than 1 in 1000..
As yet the hospitalisation figures have not shown similar dramatic increases, although there are some worrying very recent trends.
Mani Sarkar has conducted a two part interview with Ian Ozsvald (pydata London founder) on Kaggling (see twitter posts here and here, as well as a summary in Ian’s newsletter here)
David Higgins has been very productive on topics in medical AI, digital health and data driven business, posting an article a week from September through Christmas – lots of excellent material here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
Properly dark and cold now in the UK, and even some initial sightings of Christmas trees so it must be getting to the end of year… perhaps time for some satisfying data science reading materials while pondering what present to buy for your long lost auntie!
Following is the December edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are all conscious that times are incredibly hard for many people and are keen to help however we can- if there is anything we can do to help those who have been laid-off (networking and introductions help, advice on development etc.) don’t hesitate to drop us a line.
On Tuesday 23rd November we hosted our latest event “The National AI Strategy – boom or bust to your career in data science?” and it was another great success with a strong turnout.
First of all Seb Krier, Senior Technology Policy Researcher at the Stanford University Cyber Policy Centre, gave an excellent overview of the published National AI strategy using his extensive experience to provide insight into the strengths and weaknesses of the different focus areas, and how it compares to different approaches around the world.
Next, Adam Davison and Martin Goodson talked through the results of our recent data science practitioner survey on the government strategy proposals, highlighting areas of discrepancy and omission.
We then finished with a lively round-table discussion, additionally including Stian Westlake, Chief Executive of the RSS and Janet Bastiman, Chief Data Scientist at Napier AI.
We will publish a more detailed review and video in the coming weeks for those who missed out.
If anyone is interested in getting more involved in this discussion, we are collaborating with the UK Government’s Office for AI to host a roundtable event on AI Governance and Regulation which is one of the 3 main pillars of the UK AI Strategy. We are seeking Data Science and AI experts and practitioners to participate – please express any interest by emailing weatheralljames@hotmail.com.
"This change will represent one of the largest shifts in facial recognition usage in the technology’s history. More than a third of Facebook’s daily active users have opted in to our Face Recognition setting and are able to be recognized, and its removal will result in the deletion of more than a billion people’s individual facial recognition templates."
For example, asking AI to cure cancer as quickly as possible could be dangerous. “It would probably find ways of inducing tumours in the whole human population, so that it could run millions of experiments in parallel, using all of us as guinea pigs,” said Russell. “And that’s because that’s the solution to the objective we gave it; we just forgot to specify that you can’t use humans as guinea pigs and you can’t use up the whole GDP of the world to run your experiments and you can’t do this and you can’t do that.”
And a truly data driven attempt to combat filter bubbles and bias in the news: https://www.improvethenews.org/, where you can see news on the same topic from 100s of different news sources and filter/categorise them based on a variety of data driven dimensions including political stance, establishment stance etc. For more background on this, as well as a wide array of AI topics, I highly recommend the interview with Max Tegmark on the ‘People I Mostly Admire’ podcast.
Developments in Data Science… As always, lots of new developments…
The Conference on Neural Information Processing Systems (NIPS is one of the top machine learning conferences – a quick digest of all 2021 submissions here
“The brain is able to use information coming from the skin as if it were coming from the eyes. We don’t see with the eyes or hear with the ears, these are just the receptors, seeing and hearing in fact goes on in the brain.”
"This trend of massive investments of dozens of millions of dollars going into training ever more massive AI models appears to be here to stay, at least for now. Given these models are incredibly powerful this is very exciting, but the fact that primarily corporations with large monetary resources can create these models is worrying"
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
“Biology is likely far too complex and messy to ever be encapsulated as a simple set of neat mathematical equations. But just as mathematics turned out to be the right description language for physics, biology may turn out to be the perfect type of regime for the application of AI.”
“There was no problem with the algorithm as long as they stay within the boundaries of the business model and buy cookie-cutter homes that are easier to sell. There are a lot of things that affect the valuation of homes that even very sophisticated algorithms cannot catch"
How does that work? A new section on understanding different approaches and techniques
"Before we start, just a heads-up. We're going to be talking a lot about matrix multiplications and touching on backpropagation (the algorithm for training the model), but you don't need to know any of it beforehand. We'll add the concepts we need one at a time, with explanation.."
For example, speech recognition systems need to disambiguate between phonetically similar phrases like “recognize speech” and “wreck a nice beach”, and a language model can help pick the one that sounds the most natural in a given context. For instance, a speech recognition system transcribing a lecture on audio systems should likely prefer "recognize speech", whereas a news flash about an extraterrestrial invasion of Miami should likely prefer "wreck a nice beach".
Practical tips How to drive analytics and ML into production
We’ve previously highlighted the importance of MLOps and the standardisation of processes for updating and monitoring ML models in production. Another good podcast on the ‘The Data Exchange’ this time about ML Ops Anti-Patterns (the underlying research paper is here)
Speaking of MLOps – excellent summary of the platforms used across the big players, highlighting how much is still ‘home grown’ (labeled ‘IH’ below)
"Machine learning systems are extremely complex, and have a frustrating ability to erode abstractions between software components. This presents a wide array of challenges to the kind of iterative development that is essential for ML success.”
Bigger picture ideas Longer thought provoking reads – a few more than normal, lean back and pour a drink!
"Abundant evidence and decades of sustained research suggest that the brain cannot simply be assembling sensory information, as though it were putting together a jigsaw puzzle, to perceive its surroundings. This is borne out by the fact that the brain can construct a scene based on the light entering our eyes, even when the incoming information is noisy and ambiguous."
As we head into winter, we continue to experience the conflicting emotions of relaxing regulations and behaviour with increasing Covid prevalence and hospitals at breaking point. And now there is a news of a new variant…
The latest ONS Coronavirus infection survey estimates the current prevalence of Covid in the community in England to be roughly 1 in 65 people which is somewhat better than last month (1 in 50) but still very high… Back in May the prevalence was less than 1 in 1000..
There is increasingly scrutiny of the UK Governments policy towards Covid since the end of lockdown in July, particularly with regards to children
"Whatever the reason, by half-term, only around 16 per cent of vaccinations in the cohort had been achieved. Meanwhile, school-age kids had caught Covid by the truckload. Over 7 per cent of the entire Year 7 to Year 11 cohort was infected on any day in the last week of October alone. Maybe that was the unspoken plan. Certainly the JCVI’s minutes – released at the end of October after lengthy delays – make grim reading in this respect. The idea, already noted, that “natural infection” might be better than vaccination for young people was under discussion even here. Somehow, catching Covid was proffered as a better way of not getting ill with Covid than preventing its worst effects with a proven vaccine."
Professor Harin Sellahewa reports that nearly 50 of the University of Buckingham’s first ever master’s level data science apprentices have graduated. The Integrated Master’s level Degree Apprenticeship course was set up two years ago to help address an urgent shortage of people with advanced digital skills and to produce expert data scientists by giving them the technological and business skills to transform their workplace. The graduates receive the MSc in Applied Data Science from Buckingham as well as the Level 7 Digital and Technology Solutions Specialist degree apprenticeship certificate from ESFA. The apprenticeship is provided in partnership with AVADO who work with businesses to train staff to develop the skills needed to compete in a digital world. Industry partners such as IBM, Tableau, TigerGraph and Zizo conducted practical workshops for the learners.
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
The clocks have changed – officially the end of ‘daylight savings’ in the UK – does that mean we no longer try and save daylight? Certainly feels that way … definitely time for some satisfying data science reading materials while drying out from the rain!
Following is the November edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are all conscious that times are incredibly hard for many people and are keen to help however we can- if there is anything we can do to help those who have been laid-off (networking and introductions help, advice on development etc.) don’t hesitate to drop us a line.
We are pleased to announce our next virtual DSS meetup event, on Tuesday 23rd November at 5pm: “The National AI Strategy – boom or bust to your career in data science?”. Following on from our commentary on the UK Government’s AI Strategy (based on the excellent feedback from our community), and the pick-up we have received, we are going to run a focused event discussing this topic. You will hear key information about the strategy and have the opportunity to ask questions, provide input, and hear a panel of experts discuss the implications of the strategy for practitioners of AI in the UK. Save the date- all welcome!
Of course, the RSS never sleeps… so preparation for next year’s conference, which will take place in Aberdeen, Scotland from 12-15 September 2022, is already underway. The RSS is inviting proposals for invited topic sessions. These are put together by an individual, group of individuals or an organisation with a set of speakers who they invite to speak on a particular topic. The conference provides one of the best opportunities in the UK for anyone interested in statistics and data science to come together to share knowledge and network. Deadline for proposals is November 18th.
Exceedingly disappointing that the “racist visa algorithm” ever got implemented at the UK Home Office, but heartening to see that it has at least been withdrawn after judicial review, with Foxglove leading the charge.
“As far as we can tell, the algorithm is using problematic and biased criteria, like nationality, to choose which “stream” you get in. People from rich white countries get “Speedy Boarding”; poorer people of colour get pushed to the back of the queue.”
"Facebook has been unwilling to accept even little slivers of profit being sacrificed for safety"
New research into the immense data sets used to train the large image recognition, language and ‘multi-modal’ deep learning models highlights just how careful we need to be in data curation and cleaning
It’s not all doom and gloom though- there are positive applications of some of these AI driven tools, as this article points out, with at risk populations able to disguise their voices and gain protection via deep-fake approaches.
One thing is for sure: ethical utilisation of AI is a complex issue that is not going away any time soon – Wired calls for a ‘Bill of Rights for an AI-Powered World‘
"In a competitive marketplace, it may seem easier to cut corners. But it’s unacceptable to create AI systems that will harm many people, just as it’s unacceptable to create pharmaceuticals and other products—whether cars, children’s toys, or medical devices—that will harm many people."
Developments in Data Science… As always, lots of new developments…
Before delving into the research, it’s sometimes useful to step back and observe the lie of the land. Interesting perspective here on how the major players have ended up focusing in slightly different areas of deep learning research
Interesting research into the limits of large scale pre-training, uncovering examples where “to have a better downstream performance, we need to hurt upstream accuracy”
"It is important to not only look at average task accuracy -- which may be biased by easy or redundant tasks -- but also worst-case accuracy (i.e. the performance on the task with the lowest accuracy)."
Explainability and interpretability of large models continues to be a hot topic in research. This novel approach from the Google research team leverages GANs to explain the given classifier- very cool!
"Classification, extractive question answering, and multiple choice tasks benefit so much from additional examples that collecting a few hundred examples is often "worth" billions of parameters"
The extent to which you can use synthetic data in machine learning always generates discussion. Microsoft Research highlights you can go far with facial analysis, with the potential benefits of improving diversity in data sets.
The annual ‘State of AI’ report is always a weighty tome – this years’ comes in at 188 slides… Worth a skim to see what people are working on, but perhaps be wary of the predictions…
This is very relevant – ‘editing’ models. We have talked about how some of the large data sets used to train the leading image and language models have questionable data quality. Is there a way of removing the influence of particular erroneous data points from the final model when they are identified? Researchers at Stanford University think so
"MEND can be trained on a single GPU in less than a day even for 10 billion+ parameter models; once trained MEND enables rapid application of new edits to the pre-trained model. Our experiments with T5, GPT, BERT, and BART models show that MEND is the only approach to model editing that produces effective edits for models with tens of millions to over 10 billion parameters"
"By leveraging advances in graph neural networks, we propose a hypernetwork that can predict performant parameters in a single forward pass taking a fraction of a second, even on a CPU. The proposed model achieves surprisingly good performance on unseen and diverse networks"
Whether or not Deep Learning techniques are useful for traditional tabular data can often be a point of contention – is the additional complexity really worth it? Useful research survey here.
Finally, good to learn that it’s not just all about scale (more data, more compute)- our algorithms are getting better, at least according to research from MIT
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
Google has announced it plans to include multi-modal models in its search algorithms- learning from the linkages between text and images- good commentary here
“It holds out the promise that we can ask very complex queries and break them down into a set of simpler components, where you can get results for the different, simpler queries and then stitch them together to understand what you really want.”
Commentary from Wired (here and here) on the increasing costs of training models, and how this potentially puts the most advanced approaches out of reach of all but a very select few companies. All is not lost though – we have previously discussed many approaches to pruning and simplifying models without significant losses in accuracy, and in addition transfer learning from open source pre-trained models is now widely available. And some useful practical tips here on how to train big models cheaply..
Perhaps we’ll all end up back in spreadsheets…. AI can even help us with that though! Amazing that a language based model architecture can be used to understand and predict spreadsheet formulae…
"To compute the embedding of the tabular context, it first uses a BERT-based architecture to encode several rows above and below the target cell (together with the header row). The content in each cell includes its data type (such as numeric, string, etc.) and its value, and the cell contents present in the same row are concatenated together into a token sequence to be embedded using the BERT encoder”
How does that work? A new section on understanding different approaches and techniques
Why do neural networks generalise so well? Good question… let the BAIR help you out (well worth a read – note you may need to reload the page as it doesnt seem to take in-bound links)
"Perhaps the greatest of these mysteries has been the question of generalization: why do the functions learned by neural networks generalize so well to unseen data? From the perspective of classical ML, neural nets’ high performance is a surprise given that they are so overparameterized that they could easily represent countless poorly-generalizing functions."
"Nobody cared that I speak 5 languages, that I know a bunch about how microcontrollers work in the tiniest of details, how an analog high-frequency circuit is built from bare metal, and how computers actually work. All of that is abstracted away. You only need…algorithms & data structures pretty much.”
Bigger picture ideas Longer thought provoking reads – a few more than normal, lean back and pour a drink!
"A number of researchers are showing that idealized versions of these powerful networks are mathematically equivalent to older, simpler machine learning models called kernel machines. If this equivalence can be extended beyond idealized neural networks, it may explain how practical ANNs achieve their astonishing results."
Less AI related and more philosophical around the scale of information available and what that means for attention… ‘stepping out of the firehose’, well worth a read from Benedict Evans.
"I wrote earlier this year about Morioka Shoten, a bookshop in Tokyo that only sells one book, and you could see this as an extreme reaction to a problem of infinite choice. Of course, like all these solutions it really only relocates the problem, because now you have to know about the shop instead of having to know about the book"
Practical Projects and Learning Opportunities As always here are a few potential practical projects to keep you busy:
"Transcribing Japanese cursive writing found in historical literary works like this one is usually an arduous task even for experienced researchers. So we tested a machine learning model called KuroNet to transcribe these historical scripts."
"A competition focused on helping advance development of next-generation virtual assistants that will assist humans in completing real-world tasks by harnessing generalizable AI methodologies such as continuous learning, teachable AI, multimodal understanding, and reasoning"
Covid Corner
Although life seems to be returning to normal for many people in the UK, there is still lots of uncertainty on the Covid front… booster vaccinations are now rolling out in the UK, which is good news, but we still have exceedingly high community covid case levels due to the Delta variant and rising hospitalisations…
The latest ONS Coronavirus infection survey estimates the current prevalence of Covid in the community in England to be roughly 1 in 50 people as high as it has ever been – crazy to think that 2% of the UK population have Covid right now… Back in May the prevalence was less than 1 in 1000..
"From the viewpoint of some JCVI members, children aren’t independent agents with a right to be protected from a potentially dangerous virus. Rather, because they can serve as human shields for more vulnerable adults, it’s downright good when children get sick. They explicitly stated that “natural infection in children could have substantial long-term benefits for COVID-19 in the UK.” Not only is this scientific nonsense, as the high number of infections in the UK clearly shows, it’s a moral abomination"
Sarah Phelps invites everyone to what looks to be an excellent webinar hosted by the UK ONS Data Science Campus:
“The UK Office for National Statistics Data Science Campus and UNECE HLG-MOS invite you to join them for the ONS-UNECE Machine Learning Group 2021 Webinar on 19 November. “
“The webinar will provide an opportunity to learn about the progress that the Group has made this year in its different work areas, from coding and classification and satellite imagery to operationalisation and data ethics. Bringing together colleagues from across the global official statistics community, it will include contributions from senior figures in the data science divisions of various NSOs as well as discussion on the priorities for advancing the use of machine learning in official statistics in 2022.”
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
I guess summer is over, what there was of it- I was hoping we might get a bit of autumn sunshine but it feels like it’s big coat weather already… definitely time for some tasty data science reading materials in front of a warm fire!
Following is the October edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
We are all conscious that times are incredibly hard for many people and are keen to help however we can- if there is anything we can do to help those who have been laid-off (networking and introductions help, advice on development etc.) don’t hesitate to drop us a line.
First of all, we have a new name… Data Science and AI Section! To be honest, we’ve always talked about machine learning and artificial intelligence, and have some very experienced practitioners both on the committee and in our network, so it doesn’t really change our focus. It is nice to have it officially recognised by the RSS though.
Thank you all for taking the time to fill in our survey responding to the UK Government’s proposed AI Strategy. As you may have seen, Martin Goodson, our chair, summarised some of the findings in a recent post, highlighting the significant gaps in the government’s proposed approach based on comments from you. Some of these gaps, particularly on open-source, have now been publicly acknowledged, multiple times. In addition Martin, and Jim Weatherall met with Sana Khareghani (director of the Office for AI) and Tabitha Goldstaub (chair of the AI council) in order to further advocate for our community’s needs, with Sana agreeing that the Office for AI will run workshops together with the RSS focused on the technical practitioner community, in order to gain their perspective and identify their needs.
“Confessions of a Data Scientist” seemed to go down very well at the recent RSS conference- massive thanks to Louisa Nolan for making it so successful, and to you all for your contributions.
Of course, the RSS never sleeps… so preparation for next year’s conference, which will take place in Aberdeen, Scotland from 12-15 September 2022, is already underway. The RSS is inviting proposals for invited topic sessions. These are put together by an individual, group of individuals or an organisation with a set of speakers who they invite to speak on a particular topic. The conference provides one of the best opportunities in the UK for anyone interested in statistics and data science to come together to share knowledge and network. Deadline for proposals is November 18th.
Lots of exciting data science going on, as always!
Ethics and more ethics… Bias, ethics and diversity continue to be hot topics in data science…
Last month in the ethics section we mentioned the recent Australian court case, where an AI was recognised as the inventor in a patent. This issue is now coming to a head in different jurisdictions, including the US and UK: useful summaries from the Register and the verge, with a more in-depth look at the legal side from Pinsent Masons here
The UN High Commissioner for Human Rights released an urgent call for action around AI risks to privacy
“Artificial intelligence can be a force for good, helping societies overcome some of the great challenges of our times. But AI technologies can have negative, even catastrophic, effects if they are used without sufficient regard to how they affect people’s human rights”
Meantime, new applications of AI highlight these risks…:
And of course we know how fragile some of these systems are to adversarial attack (tricking the AI with something that is obvious to a human). It seems you can now avoid facial recognition with some simple makeup.
Medical AI is rapidly developing and there are questions as to whether and how medical practitioners keep to up speed with the pros and cons of different approaches and the ethical challenges that occur – good paper talking through the issues
Recommendation systems are everywhere and increasingly simple to implement.
Facebook has tacitly admitted that engagement might not be the most appropriate measure to optimise – which would be big news if they move in that direction
"Depoliticizing people’s feeds makes sense for a company that is perpetually in hot water for its alleged impact on politics"
Transparency is a key component to avoiding bias and reducing ethical concerns and we have a couple of positive examples from leading firms this month
"We don’t want viewers regretting the videos they spend time watching and realized we needed to do even more to measure how much value you get from your time on YouTube."
Developments in Data Science… As always, lots of new developments… thought we’d have a more extended look at some of the new research this month
Plenty of great arXiv papers out there this month- I know these can be a bit dry, so will try and give a bit of context…
One theme of research we have been following is “fewer-shot” training of models. Fundamentally, humans don’t need millions of examples of an orange before being able to identify one, so learning from limited examples should be possible. Large language models like GPT-3 have shown great promise in this area, where, given a few “prompts” (question and answer examples), they seem to be able to provide remarkable results to this type or problem. Sadly, this paper, “true few-shot learning” suggests we need a more standardised approach to example selection as previous results may have been artificially inflated by biased approaches.
More positively, “Can you learn an algorithm” talks through recent research showing that simple recurrent neural networks can learn approaches that can be successfully applied to larger scale problems, just as humans can learn from toy examples. Similarly, a new sequence to sequence learning approach from MIT CSAIL includes a component that learns “grammar” across examples.
Another popular research theme is simplifying architecture and reducing processing. A team at Google Brain have shown (“Pay Attention to MLPs“) that you can almost replicate the performance of transformers (a more complex deep learning architecture) with a simpler approach based on basic building blocks (multi-layer perceptrons)
Of course the big industrial research powerhouses (Google/DeepMind, Facebook etc.) keep churning out fantastic work:
Facebook released textless-NLP which generates speech direct from audio. It is based on an underlying Generative Spoken Language Model which can thus work on languages without huge text corpuses. They have also released a new approach to search, based on what they call ‘neural-databases’ which could greatly improve results to complex queries.
“We would like our agents to leverage knowledge acquired in previous tasks to learn a new task more quickly, in the same way that a cook will have an easier time learning a new recipe than someone who has never prepared a dish before"
Finally, one paper I encourage everyone to read- “A Farewell to the Bias-Variance Tradeoff?“, one of the conundrums I still struggle to fully understand … why is that over-parameterised models (those which seem to have far too many parameters given the data set they are trained on) are able to generalise so well.
Real world applications of Data Science Lots of practical examples making a difference in the real world this month!
Great article in Wired on the development of large language models outside of the US, and the English language
"What's surprising about these large language models is how much they know about how the world works simply from reading all the stuff that they can find"
Interesting overview on current state of the art in “creative automation” (“the ability to generate original, high quality content leveraging data and technology”) – lots of fun things to try out!
Google has released a new approach to “upscaling” photos – removing that pixelated effect – with impressive results.
SpaceCows …. you had me with the name! Tracking feral cattle and buffalo across Northern Australia (a 25,000 square kilometre area) with 25 nano satellites and ML image recognition
"It is a pioneering program that’s mixing responsible AI and science with indigenous led knowledge and solving complex environmental management problems at spots in Northern Australia"
We don’t hear much from Amazon about their use of AI, although clearly they have very advanced applications across their business. This was an interesting post digging into the practical problem of how you help delivery workers find the actual entrance to a given residence, from noisy data.
“In this project, we’ve trained physically simulated humanoids to play a simplified version of 2v2 football” …. and there’s video!
And the Boston Dynamics robots continue to fascinate/scare in equal measure… they can now do Parkour!
"On the Atlas project, we use parkour as an experimental theme to study problems related to rapid behavior creation, dynamic locomotion, and connections between perception and control that allow the robot to adapt – quite literally – on the fly."
Finally really interesting background on developments in protein structure after DeepMind’s alpha fold announcement and the concern that the underlying code might not be released.
"Everyone was floored, there was a lot of press, and then it was radio silence, basically. You’re in this weird situation where there’s been this major advance in your field, but you can’t build on it.”
How does that work? A new section on understanding different approaches and techniques
Hyper-parameter optimisation can often require more art than science if you don’t have a systematic approach- some useful tips here using Argo
There are lots of different activation functions (defining the output from given inputs) you can use in neural networks, but which one should you use for a given task? Useful paper here.
I’m not a massive fan of media-mix modelling (building models that optmise marketing expenditure based on historic performance) because it always feels there is so much fundamentally missing in the underying data sets. However, they can certainly be useful, and using a Bayesian approach would seem to be a good way to go (more detail here)
"The Bayesian approach allows prior knowledge to be elegantly incorporated into the model and quantified with the appropriate mathematical distributions."
You have your model in production, but you need to make it faster…
Interesting take on how best to apply ML Ops in your organisation
"Companies that are starting with the problem first, improving on a defined metric and reach ML as a solution naturally are the ones that will treat their models as a continuously developing product”
We’ve talked about “Data-centric AI” previously and are advocates…
"We call for the replacement of the deep network technology to make it closer to how the brain works by replacing each simple unit in the deep network today with a unit that represents a neuron, which is already—on its own—deep"
What’s interesting with that system, contrary to classical game development, is that you don’t need to hard-code every interaction. Instead, you use a language model that selects what’s robot possible action is the most appropriate given user input.
Our goal is to create a formal call for blog posts at ICLR to incentivize and reward researchers to review past work and summarize the outcomes, develop new intuitions, or highlight some shortcomings.
Covid Corner
Although life seems to be returning to normal for many people in the UK, there is still lots of uncertainty on the Covid front… vaccinations keep progressing in the UK, which is good news, but we still have high community covid case levels due to the Delta variant…
The latest ONS Coronavirus infection survey estimates the current prevalence of Covid in the community in England to be roughly 1 in 85 people, which is still very high, but at least better than the 1 in 70 a month or so ago.
"By comparing Eva’s performance against modelled counterfactual scenarios, we show that Eva identified 1.85 times as many asymptomatic, infected travellers as random surveillance testing, with up to 2-4 times as many during peak travel, and 1.25-1.45 times as many asymptomatic, infected travellers as testing policies that only utilize epidemiological metrics."
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS