
Hi everyone-
Welcome to July! Inflation, union strikes, sunshine … lots of commentary drawing parallels to the mid-70s. One thing that is very different from that period is the world of data science (which didn’t even exist as a discipline) – crazy to think that the Apple II launched in ’77 with 4 KB RAM, 4 million times less memory than the laptop I’m writing this on…
Following is the July edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. We’ll take a break in August, so fingers crossed this sees you through to the beginning of September…
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science July 2022 Newsletter
RSS Data Science Section
Committee Activities
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with plans underway to launch the Advanced Certificate shortly.
We are very excited to announce our next meetup, “From paper to pitch, success in academic/industry collaboration” which will take place on Wednesday 20th July from 7pm-9pm. We believe that there is huge potential in greater collaboration between industry and academia and have invited two excellent speakers to provide examples of how this can work in practice. This should be a thought provoking, and very relevant (and free) event – sign up here.
The full programme is now available for the September RSS 2022 Conference. The Data Science and AI Section is running what will undoubtedly be the best session(!) … ‘The secret sauce of open source’, which will discuss using open source to bridge the gap between academia and industry.
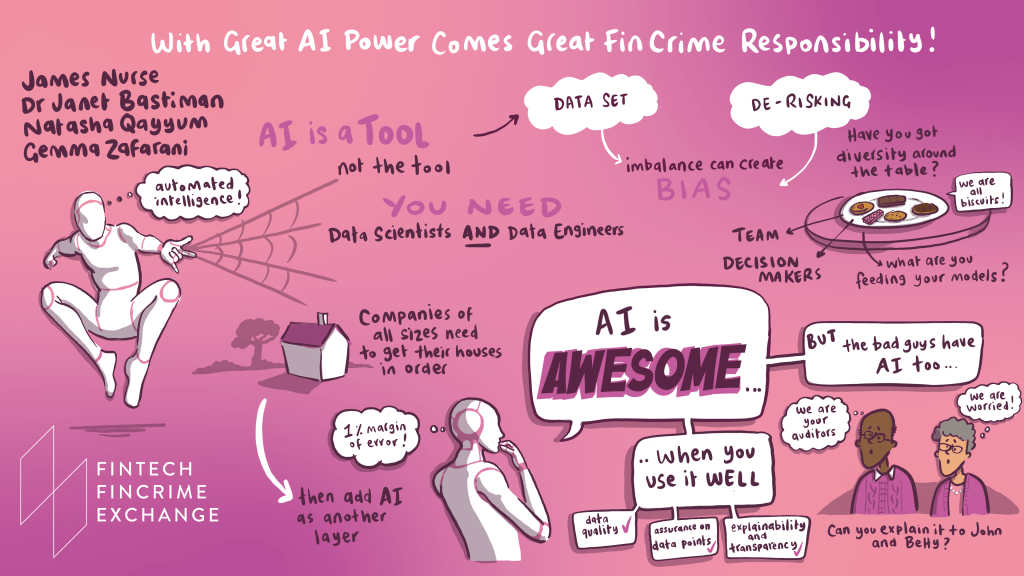
As mentioned last time, Janet Bastiman (Chief Data Scientist at Napier AI) recently spoke at the FinTech FinCrime Exchange Conference (FFECON) in a panel session entitled “With great AI power comes great FinCrime responsibility”: cool summary from the discussion…
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The next event will be on July 13th when Stéphane d’Ascoli, Ph.D. candidate at Facebook AI, discusses “Solving Symbolic Regression with Transformers“. Videos are posted on the meetup youtube channel – and future events will be posted here.
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
- Let’s start with some positives for a change!
- We know that the AI community has a diversity problem… DeepMind is doing it’s bit to try and address this by actively working with underrepresented groups (‘Leading a movement to strengthen machine learning in Africa‘, ‘Advocating for the LGBTQ+ community in AI research‘)
- And some acknowledgment in the courts that current commercially available AI tools may not be ready for critical decision making – “Oregon dropping AI tool used in child abuse cases
"From California to Colorado and Pennsylvania, as child welfare agencies use or consider implementing algorithms, an AP review identified concerns about transparency, reliability and racial disparities in the use of the technology, including their potential to harden bias in the child welfare system."- Also some interesting developments and frameworks from the research community:
- An approach to try and codify the ‘values’ that are encoded in a machine learning model, making it easier to identify appropriate use-cases and potential pitfalls
- A proposed approach for designing a third party audit ecosystem for AI governance
- The Large Language Models (such as GPT3 – good background from the economist on foundation models here) that underly much of the recent breakthroughs in natural language processing and applications such as chat-bots are trained on vast quantities of text. By focusing the training on particular types of text, you can, relatively easily, produce models with certain “character”
- For instance, Ruth Bader Ginsburg.
- One researcher trained a model on the toxic 4chan usergroups ‘with entirely predictable results‘, resulting in public condemnation from many AI luminaries. Good background and commentary here
"In summary, GPT-4chan resulted in a large amount of public discussion and media coverage, with AI researchers generally being critical of Kilcher’s actions and many others disagreeing with these criticisms. This sequence of events was generally predictable, so much so that I was able to prompt GPT-3 – which has no knowledge whatsoever about current events – to summarize the controversy somewhat accurately"- Given all this, good to see some “best practices for deploying language models” being published.
"Cohere, OpenAI, and AI21 Labs have developed a preliminary set of best practices applicable to any organization developing or deploying large language models. Computers that can read and write are here, and they have the potential to fundamentally impact daily life.
The future of human-machine interaction is full of possibility and promise, but any powerful technology needs careful deployment. The joint statement below represents a step towards building a community to address the global challenges presented by AI progress, and we encourage other organizations who would like to participate to get in touch."- Of course the sad truth is that, in simplistic terms, this type of model is basically regurgitating the same biases present in the material it was trained on. Some thought provoking analysis from textio highlighting the inherent biases present in performance feedback.
- A Google researcher (since placed on administrative leave…) caused controversy by claiming that one of these Large Language Models (in this case Google’s LaMDA) was sentient- good summary in Wired here. The guardian followed up on this with some thoughtful pieces on how the model works, and why we are prone to be fooled by mimicry.
- Facebook (Meta) apparently made millions in advertising revenue from accounts that it knew to be fake – this misalignment of commercial incentives is why content creators are looking to the courts to redress the balance.
"It’s strategic transparency. They get to come out and say they're helping researchers and they're fighting misinformation on their platforms, but they're not really showing the whole picture.”- With the proliferation of data available in the modern world, AI is often thought of as a critical tool for intelligence services to quickly identify potential threats. But the current approaches may not be the ‘silver bullet’ hoped for…
"While AI can calculate, retrieve, and employ programming that performs limited rational analyses, it lacks the calculus to properly dissect more emotional or unconscious components of human intelligence that are described by psychologists as system 1 thinking."- This is not stopping implementation around the world however. The NYTimes dug into China’s increasing use of surveillance technology on its citizens
"China’s ambition to collect a staggering amount of personal data from everyday citizens is more expansive than previously known, a Times investigation has found. Phone-tracking devices are now everywhere. The police are creating some of the largest DNA databases in the world. And the authorities are building upon facial recognition technology to collect voice prints from the general public."- And the shocking US Supreme Court Decision to overturn Roe vs Wade has led to increased awareness of the proliferation of data available even in the US, with US women deleting their period tracking apps, and increased concerns over illicit surveillance.
"Police can not only obtain search histories from a pregnant person’s device, but can also obtain records directly from search engines, and sometimes they don’t even need a warrant."Developments in Data Science…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
- Continuing our large language model theme…
- How do we measure progress in the performance of language models? With the increasing sophistication, size and scope of these models, the traditional performance tests may not be adequate, so a new and far reaching set of tests are proposed in “Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models”
- Exploring evolution using large language models – elegant approach using feedback loops and AI-generated programming code
- And in a similar vein, digging into the emergent abilities of large language models as the size of the model gets larger.
"We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models"- Of course large language models are inherently ‘Large’ … so ways of making them more efficient are active areas of research – “DeepNet: Scaling Transformers to 1,000 Layers”
- This looks particularly innovative, and very much inline with the ‘data centric’ view of machine learning – how do you focus training on the points that are most informative
"To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant."- Transformers are the building blocks of many NLP techniques, and are now increasingly being used in Video – here an approach using transformers for video compression, and even in Reinforcement learning – here showing how transformers help in model generalisation.
- Almost by definition, improving model generalisation (ie predictions on new examples) is at the core of any research. “VOS: Learning What You Don’t Know by Virtual Outlier Synthesis” directly addresses this by focusing on detecting out of distribution examples.
- And in my continuous search to find models that work better than good old xgboost on tabular data (!), how about ‘Hopfield Networks’?
"In experiments on medium-sized tabular data with about 10,000 samples, Hopular outperforms XGBoost, CatBoost, LightGBM and a state-of-the art Deep Learning method designed for tabular data"- Facebook/Meta continues to make progress in direct speech to speech which as a concept is very impressive (“these models directly translate source speech into target speech spectrograms”)
- Google has improved its video captioning using novel pre-training- good explanation of how it works here
- Intriguing and perhaps controversial call for more qualitative research in AI from the team at Fast.ai
- Finally, who needs Dall-e when you’ve got Parti
"Parti treats text-to-image generation as a sequence-to-sequence modeling problem, analogous to machine translation – this allows it to benefit from advances in large language models, especially capabilities that are unlocked by scaling data and model sizes"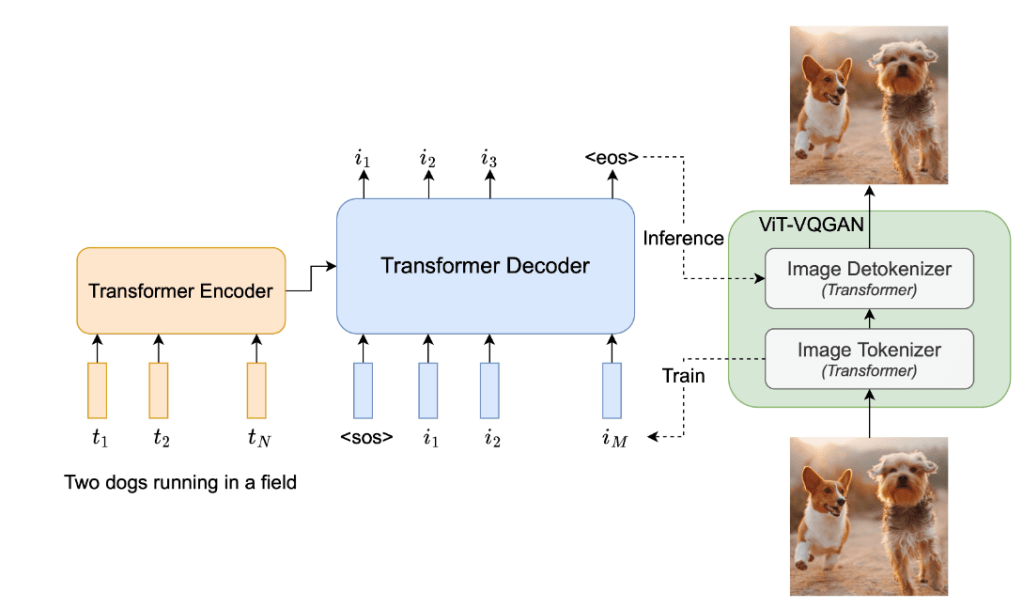

Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
- Robots are becoming increasingly sophisticated but making them context aware is still a challenge – this looks like excellent progress (“This Warehouse Robot Reads Human Body Language“)
- Autonomous vehicles have not quite lived up to the hype so far – mostly because it is a very hard problem to solve – but progress is still being made in narrow use cases. Cruise is now live with driver-less taxis in San Fransisco; and Baidu in China is now building robo-cars
- Like it or not, with the rise of GPT3 more and more content is being ‘auto-generated’ – with web advertising copy a particular niche.
- Applying ML techniques to satelitte imagery still feels like an area with many more use cases, as coverage becomes more frequent and granular (nice example here of mapping urban trees) but there are still challenges, particularly in taking action on the outputs
- A reasonably obvious but perhaps not hugely popular ML application – identifying tax fraud
- An excellent use of more sophisticated forecasting methods at Google to help predict wind velocities and so better manage wind power applications – with the first commercial application in France
"Using a neural network trained on widely available weather forecasts and historical turbine data, we configured the DeepMind system to predict wind power output 36 hours ahead of actual generation. Based on these predictions, our model recommends how to make optimal hourly delivery commitments to the power grid a full day in advance"- More great applications from DeepMind – excellent interview with Demis Hassabis on how DeepMind is enabling discovery in medicine, well worth a read.
"This was AlphaFold 2, which was published in July 2021. It had a level of atomic accuracy of less than one angstrom. I work with a lot of colleagues in structural biology. They've spent years to determine the structure of a protein and many times they never solve it. But not only do you produce confidence measures, you also — anyone — can put in their favorite protein and see how it works in seconds. And you also get feedback from the user. You also linked up with the European Bioinformatics Institute (EMBL-EBI). It's open-source and it's free."- When it comes to speed, it’s tough to beat light … so how about a photonic deep neural network for image classification – amazing!
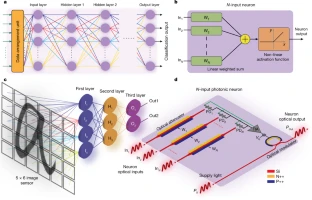
- Although there is increasing progress in quantum computing, the framing of problems in ways that can utilise the quantum approach is far from straightforward. Interesting paper showing how to do this for some simple real world examples
More DALL-E fun..
DALL-E is still making headlines so we’ll keep serving up a few fun posts!
- The excellent open source pioneers Hugging Face have released a free (mini) version of DALL-E that anyone can play with… go on, you know you want to! – together with an excellent tutorial on how these annotated diffusion models work (with pytorch code)
- This increased access has caused a lot more experimentation… including my current favourite, Kermit the frog in various film settings

- An interesting take on some of the limitations here
- And even research into the “hidden vocabulary of DALLE-2”
"We discover that DALLE-2 seems to have a hidden vocabulary that can be used to generate images with absurd prompts. For example, it seems that \texttt{Apoploe vesrreaitais} means birds and \texttt{Contarra ccetnxniams luryca tanniounons} (sometimes) means bugs or pests"How does that work?
Tutorials and deep dives on different approaches and techniques
- Another Transformer tutorial with code!
- Getting deep into training times and costs … “How fast can we perform a single pass?”
- Useful tutorial with code exploring seizure data, looking for predictors of seizure events
- How would you create a diagram with code? With ‘diagrams‘
- In the market for training, evaluating and serving sequence models? T5X looks worth a try
- Detailed look at a 2 tier recommendation system
"An important point: if you train the first level on the whole dataset first and then the second level, you will get a leakage in the data. At the second level, the content score of matrix factorization will take into account the targeting information"- You’ve been wanting to explore GPT-3 but haven’t known where to start? Here you go!
"I think a big reason people have been put off trying out GPT-3 is that OpenAI market it as the OpenAI API. This sounds like something that’s going to require quite a bit of work to get started with.
But access to the API includes access to the GPT-3 playground, which is an interface that is incredibly easy to use. You get a text box, you type things in it, you press the “Execute” button. That’s all you need to know.."- I’m a regular user of Jupyter Lab (and notebooks) … but I’ve never used it build a web app! Lots of useful tips here
- And … it’s live! Andrew Ng’s new foundational course in Machine Learning is open for enrolment – if you do one course, do this one
"Newly rebuilt and expanded into 3 courses, the updated Specialization teaches foundational AI concepts through an intuitive visual approach, before introducing the code needed to implement the algorithms and the underlying math."Practical tips
How to drive analytics and ML into production
- In some ways data engineering and MLOps are getting easier, in that there are more services available … but navigating the choices doesn’t get any easier!
- A look at how LinkedIn handles MLOps
- A couple of good reddit threads:
- Resources for honing your SQL skills
- And tips and tricks to improve ML model performance – great to see the answer is … data!
- How best to structure data teams across an organisation is a question that has no best answer. Certainly centralisation makes a lot of sense unless you are in a very sophisticated data savvy organisation…. Facebook have only just made the decision to decentralise
Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink! A few extra this month to get you through the long summer…
- Yann LeCun goes deep – “What can AI tell us about intelligence“, delving into the hot-topic of symbolic reasoning
"At the heart of this debate are two different visions of the role of symbols in intelligence, both biological and mechanical: one holds that symbolic reasoning must be hard-coded from the outset and the other holds it can be learned through experience, by machines and humans alike. As such, the stakes are not just about the most practical way forward, but also how we should understand human intelligence — and, thus, how we should pursue human-level artificial intelligence."- And, as always Gary Marcus is ready with a response
"Now it is true that GPT-3 is genuinely better than GPT-2, and maybe true that InstructGPT is genuinely better than GPT-3. I do think that for any given example, the probability of a correct answer has gone up...
...But I see no reason whatsoever to think that the underlying problem — a lack of cognitive models of the world —have been remedied. The improvements, such as they are, come, primarily because the newer models have larger and larger sets of data about how human beings use word sequences, and bigger word sequences are certainly helpful for pattern matching machines. But they still don’t convey genuine comprehension, and so they are still very easy for Ernie and me (or anyone else who cares to try) to break.- Somewhere in the middle lies Mike Loukides at O’Reilly
"There’s an important point about expertise hidden in here: we expect our AGIs to be “experts” (to beat top-level Chess and Go players), but as a human, I’m only fair at chess and poor at Go. Does human intelligence require expertise? (Hint: re-read Turing’s original paper about the Imitation Game, and check the computer’s answers.) And if so, what kind of expertise? Humans are capable of broad but limited expertise in many areas, combined with deep expertise in a small number of areas. So this argument is really about terminology: could Gato be a step towards human-level intelligence (limited expertise for a large number of tasks), but not general intelligence?"- And another somewhat pragmatic view using the interesting ‘language model plays chess’ example (treating chess moves as words that are fed into the model)
For those not well-versed in chess, here’s a summary of what happened. The first three or four moves were a fairly standard opening from both sides. Then, the AI began making massive blunders, even throwing away its queen. Finally, as the vice began to close around its king, the AI eventually made an illegal move, losing the game.
All in all, a pretty solid showing: it understood the format, (mostly) knew what moves were legal, and even played a decent opening. But this AI is not good at chess. Certainly, nothing close to 5000 ELO.
Is this just a “flub”, which will be fixed by scale? Will a future, even-larger GPT be the world chess champion? I don’t believe so.- Getting more philosophical – “The Imitation of Consciousness: On the Present and Future of Natural Language Processing”
"In January, 2021, Microsoft filed a patent to reincarnate people digitally through distinct voice fonts appended to lingual identities garnered from their social media accounts. I don’t see any reason why it can’t work. I believe that, if my grandchildren want to ask me a question after I’m dead, they will have access to a machine that will give them an answer and in my voice. That’s not a “new soul.” It is a mechanical tongue, an artificial person, a virtual being. The application of machine learning to natural language processing achieves the imitation of consciousness, not consciousness itself, and it is not science fiction. It is now."- Don’t worry – if we eventually get to an artificial general intelligence that everyone agrees on, we have a thoughtful taxonomy of all the ways it could kill us (AGI ruin: a list of lethalities)!
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
- Fun practical project- “In search of the least viewed article on Wikipedia“
- And maybe some useful pointers if you happen to be training small diffusion models…
- The Literary History of Artificial Intelligence…
- Finally – very cool- explore alternative histories with GPT-3
Covid Corner
Apparently Covid is over – certainly there are very limited restrictions in the UK now
- The latest results from the ONS tracking study estimate 1 in 30 people in England (1 in 18 in Scotland) have Covid. Sadly this has risen (from 1 in 60 last month) due to infections compatible with Omicron variants BA.4 and BA.5, but is at least down on it’s peak when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
- Promising research on the use of fitness tracker data to detect Covid early
Updates from Members and Contributors
- Arthur Turrell has some excellent updates from the ONS Data Science Campus:
- The ONS Data Science Campus was involved in this widely covered ONS piece on the cost of living inspired by Jack Monroe and other food campaigners.
- ‘Making text count: Economic forecasting using newspaper text’, which was a collaboration across multiple institutions and for which I am a co-author, was published in the journal of applied econometrics and shows how machine learning + text from newspaper can improve macroeconomic forecasts.
- We released a package from the Campus for evaluating how well synthetic data matches real data. Repository here, blog post here.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
- EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
- AstraZeneca are looking for a Data Science and AI Engagement lead – more details here
- The ONS Data Science Campus are looking for a Lecturer in Data Science – more details here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
