
Hi everyone-
It’s June already – time flies – and in the UK an extra bank holiday! Perhaps the data science reading materials below might help fill the void now the Jubilee celebrations have finished …
Following is the June edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science June 2022 Newsletter
RSS Data Science Section
Committee Activities
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with a plan to launch the Advanced Certificate in the summer.
We will also shortly be announcing details of our next meetup – watch this space!
Janet Bastiman (Chief Data Scientist at Napier AI) recently spoke at the FinTech FinCrime Exchange Conference (FFECON) in a panel session entitled “With great AI power comes great FinCrime responsibility”, discussing how AI implementations can go wrong and what we need to do about it.
The RSS is running an in-person Discussion Meeting on Thursday June 16th at the Errol Street headquarters: “Statistical Aspects of the Covid-19 Pandemic”. Register here for free attendance.
The full programme is now available for the September RSS 2022 Conference. The Data Science and AI Section is running what will undoubtedly be the best session(!) … ‘The secret sauce of open source’, which will discuss using open source to bridge the gap between academia and industry. An early booking registration discount is available until 6 June for in-person attendance at the conference and 20 June for viewing content via the online conference platform.
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on June 15th when Ting Chen from Google Brain, will discuss Pix2Seq, “A new language interface for object detection“. Videos are posted on the meetup youtube channel – and future events will be posted here.
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
- Last month we highlighted how increasingly prevalent ‘fakes’ are on digital platforms (uncovering over 1,000 AI-generated LinkedIn faces across 70 different businesses) – now research indicates we tend to trust fake faces more than real ones
"After three separate experiments, the researchers found the AI-created synthetic faces were on average rated 7.7% more trustworthy than the average rating for real faces... The three faces rated most trustworthy were fake, while the four faces rated most untrustworthy were real, according to the magazine New Scientist."- A positive step in restricting the use of private information – the ACLU (American Civil Liberties Union) has successfully settled their case with facial recognition company Clearview AI (more commentary here).
"The settlement, filed Monday in a federal court in Illinois, bars the company from selling its biometric data to most businesses and private firms across the U.S. The company also agreed to stop offering free trial accounts to individual police officers without their employers' knowing or approving, which had allowed them to run searches outside of police departments' purview"- Sadly, private information is still readily available even if unintentionally. Motherboard digs into “Data Broker Is Selling Location Data of People Who Visit Abortion Clinics” – while the data provider, SafeGraph, explains what happened
- Clearly the definition of private information is becoming increasingly complex: “Artificial intelligence predicts patients’ race from their medical images” – really interesting article that digs into how this is possible.
"Even when you filter medical images past where the images are recognizable as medical images at all, deep models maintain a very high performance. That is concerning because superhuman capacities are generally much more difficult to control, regulate, and prevent from harming people."- A new threat is emerging for AI – ‘data poisoning’ (planting deliberately miss-labeled training data to force miss-classification – see also ‘undetectable backdoors’). In a somewhat similar vein here is a pretty comprehensive survey of adversarial attacks and defences
- Clearly lots of potential threats from AI, so good to see the different areas of AI Safety research
"This brief focuses on three sub-areas within “AI safety,” a term that has come to refer primarily to technical research (i.e., not legal, political, social, etc. research) that aims to identify and avoid unintended AI behavior. AI safety research primarily seeks to make progress on technical aspects of the many socio-technical challenges that have come along with progress in machine learning over the past decade."- One key way of combating the use of large volumes of personal information in model training is through Federated Learning where models are trained across decentralised edge devices without exchanging data. Looks like Alibaba has made a good deal of progress in this space
- While national governments are conscious of an AI ‘arms-race’ and are crafting national strategies (e.g. here from the US), is this creating a new colonial world order?
"The AI industry does not seek to capture land as the conquistadors of the Caribbean and Latin America did, but the same desire for profit drives it to expand its reach. The more users a company can acquire for its products, the more subjects it can have for its algorithms, and the more resources—data—it can harvest from their activities, their movements, and even their bodies."- Interesting assessment of societal implications of Large Language Models from the University of Michigan Ford School of Public Policy
- Finally – intellectual property … is AI breaking patent law? Followed by some practical tips from Pete Warden on how to protect your ML models and IP
"The answers are complex and depend to some extent on your exact threat models, but if you want a summary of the advice I usually give it boils down to:
- Treat your training data like you do your traditional source code.
- Treat your model files like compiled executables."Developments in Data Science…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
- Really interesting discussion from DeepMind on “specification gaming” – the unintended consequences when you are not specific enough in defining your goal
"Another class of specification gaming examples comes from the agent exploiting simulator bugs. For example, a simulated robot that was supposed to learn to walk figured out how to hook its legs together and slide along the ground."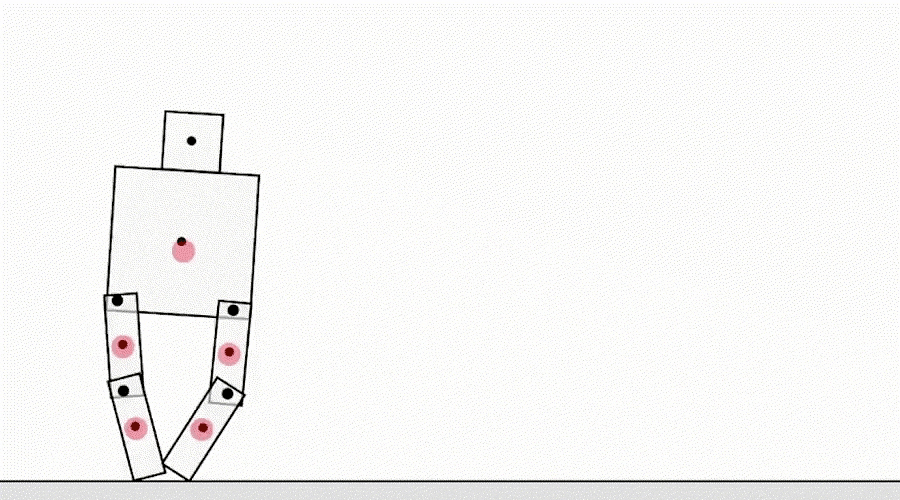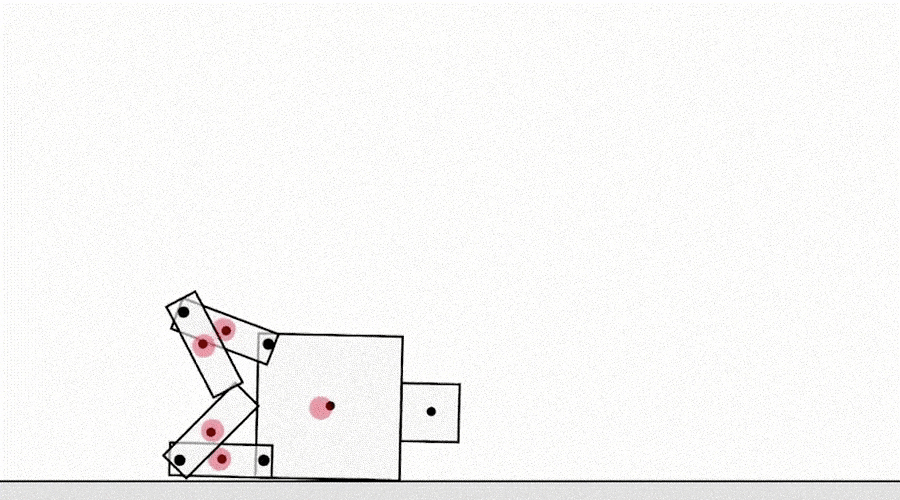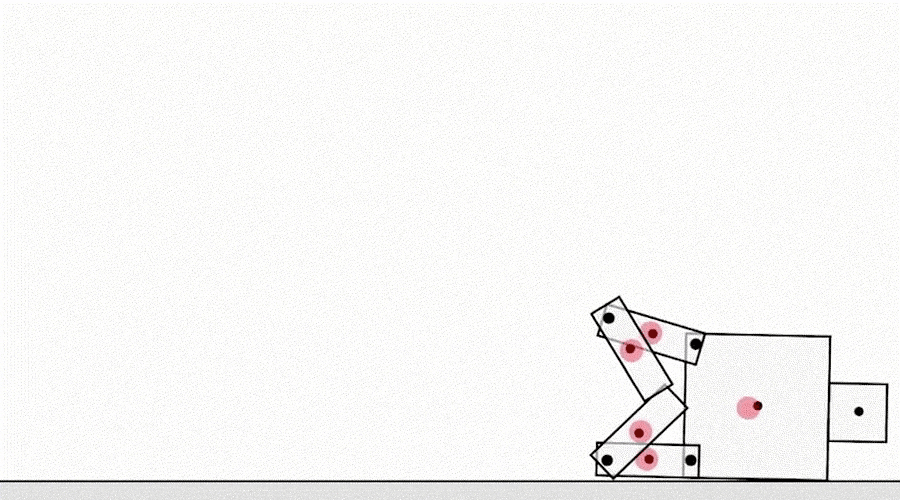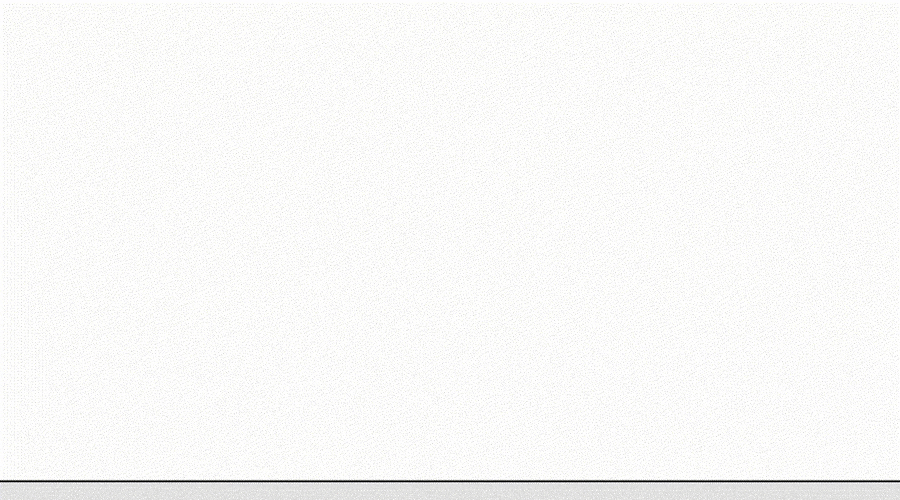
- How best can you incorporate domain specific information into general machine learning architectures – perhaps “embedded model flows” is the way forward.
- Published ML research from Apple is relatively rare – so interesting to see their publication on “Generalizing Confusion Matrix Visualization to Hierarchical and Multi-Output Labels” and its focus on practical application rather than advanced methods
- As always lots going on in the world of video:
- “A new state of the art for unsupervised computer vision” which could be very beneficial in accelerating image labelling
- Making transformers practical with “Convolutional Xformers for Vision” which reduce the computational and training data requirements
- Accessible paper from Alexia Jolicoeur-Martineau (with code and examples) on using Diffusion Models for Vision tasks
"A lot of the existing video models have poor quality (especially on long videos), require enormous amounts of GPUs/TPUs, and can only solve one specific task at a time (only prediction, only generation, or only interpolation). We aimed to improve on all these problems. We do so through a Masked Conditional Video Diffusion (MCVD) approach."- Meanwhile lots of NLP developments:
- Data augmentation is very popular for image tasks but less prevalent with text- very useful study of data augmentation approaches for NLP
- How can you fine-tune large language models with human feedback? – sounds like an important and powerful method
- Large Language Models are zero-shot learners … Crazy finding … “we show that LLMs are decent zero-shot reasoners by simply adding ‘
Let's think step by step‘ before each answer” - How do you build functioning translation models for the long tail of languages where large bi-lingual data sets are not available? Amazingly, google as figured out how to use monolingual data alone (i.e. text in one language without translation into another) using transfer learning and deep embeddings.
- Fair play to facebook/meta – they have publicly released a 175b parameter language model (OPT-175B) along with the research and training logs (which are well worth a read….the research path is never straight!)
A much broader segment of the AI community needs access to these models in order to conduct reproducible research and collectively drive the field forward. With the release of OPT-175B and smaller-scale baselines, we hope to increase the diversity of voices defining the ethical considerations of such technologies.
- DeepMind has been at its ground breaking best again …
The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
- Real world applications of reinforcement learning can still be hard to come by despite the progress at DeepMind. One promising approach is Offline RL (which utilises historic data) – looks like BAIR (Berkley Artificial Intelligence Research) has made good progress
"Let’s begin with an overview of the algorithm we study. While lots of prior work (Kumar et al., 2019; Ghosh et al., 2021; and Chen et al., 2021) share the same core algorithm, it lacks a common name. To fill this gap, we propose the term RL via Supervised Learning (RvS). We are not proposing any new algorithm but rather showing how prior work can be viewed from a unifying framework"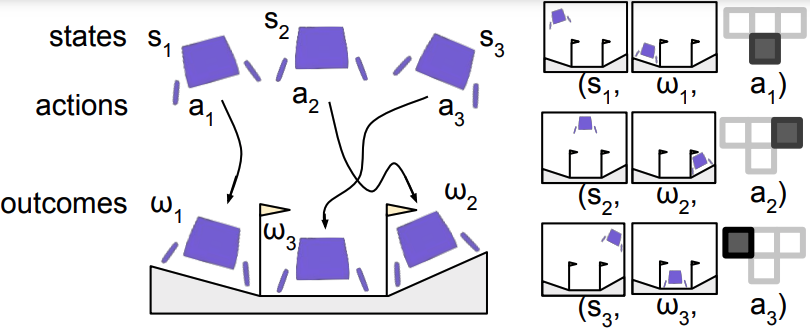
- By the way- some more good (and accessible) stuff from BAIR
- And a quick one to finish this section – useful resource summarising arXiv papers ….”Davis Summarizes Papers” (and also a great summary of ICLR 2022 papers here)
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
- I’m rather taken by these examples of Machine Learning providing us with deeper understanding of the underlying physics – this time it’s a piece of general relativity If you like this sort of thing there’s a more extended article in this vein in Quanta
- Extended piece on the state of Deep Learning for NeuroImaging
- Positive developments in leveraging robots for more mundane tasks in hospitals
- Amazon is investing in AI approaches combined with wearables to improve workplace safety
- We are doing dating all wrong … so says the data – apparently success is much more tied to your characteristics at the time and has little to do with your potential partner.. well structured article.
- Do we really need fully autonomous cars? Interesting piece from the New York Times talking through more tangible shorter term benefits
Advocates like Mr. Ward look to beneficial, low-cost, intermediate technologies that are available now. A prime example is intelligent speed assistance, or I.S.A., which uses A.I. to manage a car’s speed via in-vehicle cameras and maps. The technology will be mandatory in all new vehicles in the European Union beginning in July, but has yet to take hold in the United States.- And how about in aircraft too? “How AI could help Air Force pilots avoid costly mistakes“
- Creating images without a lens?!
- The increasing capability and affordability of drones … $200 from Snap
- Chess, Go .. how about winning at Bridge with AI
- Microsoft has apparently created an AI helper for use in Minecraft using … their AI code generator Co-Pilot
- And Google continues to innovate in search – “go beyond the search box: introducing multisearch“
At Google, we’re always dreaming up new ways to help you uncover the information you’re looking for — no matter how tricky it might be to express what you need. That’s why today, we’re introducing an entirely new way to search: using text and images at the same time. With multisearch in Lens, you can go beyond the search box and ask questions about what you see.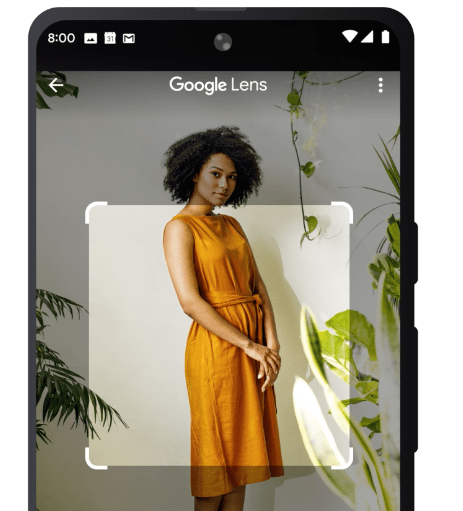
- No scary-dog robots this month … but record leaps!
More DALL-E fun..
A one off section on everyone’s favourite image generation tool, DALL-E
- Last month we highlighted the amazing examples of images generated from text prompts using OpenAI’s DALL-E 2. There’s been lots more commentary so we’ve pulled it together in one place…
- First of all, an update from OpenAI – apparently early users have generated over 3m images to date.
- How does it actually work- good breakdown of the underlying methods here.
- A different take on DALL-E and what it means for design and a potential ‘vibe-shift’ – well worth a read.
- Another great take- this time exploring how DALL-E seems to combine objects in ways that make sense but that can’t be known from the words themselves.
- Finally, watch out DALL-E, here comes IMAGEN from the Google Brain team…
"A marble statue of a Koala in front of a marble statue of a turntable. The Koala has large marble headphones"
How does that work?
Tutorials and deep dives on different approaches and techniques
- Been at least a month since a tutorial on Transformers … so here’s another good one!
- Following on from the hand-drawn approach (here) another way of thinking about Graph Neural Networks (I’m definitely biased towards the “physics inspired”!)
"Graphs are a convenient way to abstract complex systems of relations and interactions. The increasing prominence of graph-structured data from social networks to high-energy physics to chemistry, and a series of high-impact successes have made deep learning on graphs one of the hottest topics in machine learning research"- Multi-Arm Bandits for recommender systems – excellent tutorial from Eugene Yan complete with real work example implementations from Spotify, Yahoo! and Alibaba
"Recommender systems work well when we have a lot of data on user-item preferences. With a lot of data, we have high certainty about what users like. Conversely, with very little data, we have low certainty. Despite the low certainty, recommenders tend to greedily promote items that received higher engagement in the past. And because they influence how much exposure an item gets, potentially relevant items that aren’t recommended continue getting no to low engagement, perpetuating the feedback loop."- Intriguing approach – ‘supervised’ clustering using SHAP values. When you don’t have a supervised model, you just build one on a somewhat arbitrary dependent variable!
- It has been some time since we did some proper maths… get the cold cloth and a strong cup of coffee and lean in!
- Structural optimisation (with code from scratch)- interesting to see what applications of this approach their might be outside of ‘building structures’
"The goal of structural optimization is to place material in a design space so that it rests on some fixed points or “normals” and resists a set of applied forces or loads as efficiently as possible."- This is excellent from Sebastian Raschka – generating confidence intervals for machine learning classifiers
"This article outlines different methods for creating confidence intervals for machine learning models. Note that these methods also apply to deep learning. This article is purposefully short to focus on the technical execution without getting bogged down in details; there are many links to all the relevant conceptual explanations throughout this article."- Different embedding approaches (and not a mention of Word2Vec)…
- Simple, but visually elegant – understanding why splitting your data into train, test and validation is so important
- The third instalment of an excellent series on “Learning with not enough data” from Lilian Weng
- Finally, Andrew Ng is launching his new revamped ML specialisation… (the original course has been enrolled by an astonishing 4.8m people) – for a simple walk though of the key machine learning techniques have a read of his latest ‘Batch’ newsletter
"My team spent many hours debating the most important concepts to teach. We developed extensive syllabi for various topics and prototyped course units in them. Sometimes this process helped us realize that a different topic was more important, so we cut material we had developed to focus on something else. The result, I hope, is an accessible set of courses that will help anyone master the most important algorithms and concepts in machine learning today — including deep learning but also a lot of other things — and to build effective learning systems." Practical tips
How to drive analytics and ML into production
- Data Exchange Podcast (Ben Lorica) on Data Science at StitchFix
- Interesting thread on ML Ops principles – some useful pragmatic tips, well worth a look
- Ramp up your local training with accelerated pytorch training on a mac
- How do you improve data discovery in an organisation – ‘the future of data catalogs‘
"For example, when you’re in a BI tool like Looker, you inevitably think, “Do I trust this dashboard?” or “What does this metric mean?” And the last thing anyone wants to do is open up another tool (aka the traditional data catalog), search for the dashboard, and browse through metadata to answer that question.." - Thought proving post on ‘bundling into the database’
"I actually don’t care that much about the bundling argument that I will make in this post. Truthfully, I just want to argue that feature stores, metrics layers, and machine learning monitoring tools are all abstraction layers on the same underlying concepts, and 90% of companies should just implement these “applications” in SQL on top of streaming databases."- Reducing bias in your hiring process for data scientists
- Finally, some useful articles on the art of data analysis and story telling
"At its core, data storytelling is about taking the step beyond the simple relaying of data points. It’s about trying to make sense of the world and leveraging storytelling to present insights to stakeholders in a way they can understand and act on. As data scientists, we can inform and influence through data storytelling by creating personal touch points between our audience and our analysis."Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink!
- More fun and games in the philosophical debate around AGI (Artificial General Intelligence) – “Deep Learning is all you need” (Yann LeCun, Hinton, Bengio et al) – vs “we are miles away – you can’t do it without a semantic layer” (Gary Marcus)
"But this morning I woke to a new reification, a Twitter thread that expresses, out loud, the Alt Intelligence creed, from Nando de Freitas, a brilliant high-level executive at DeepMind, Alphabet’s rightly-venerated AI wing, in a declaration that AI is “all about scale now.” Indeed, in his mind (perhaps deliberately expressed with vigor to be provocative), the harder challenges in AI are already solved. “The Game is Over!”, he declares""It is a tale told by an idiot, full of sound and fury, signifying nothing". —Macbeth
"AI-generated artwork is the same as a gallery of rock faces. It is pareidolia, an illusion of art, and if culture falls for that illusion we will lose something irreplaceable. We will lose art as an act of communication, and with it, the special place of consciousness in the production of the beautiful.""AIs will make increasingly complex and important decisions, but they may make these decisions based on different criteria that could potentially go against our values. Therefore, we need a language to talk to AI for better alignment. "- “What Data Visualization Reveals: Elizabeth Palmer Peabody and the Work of Knowledge Production”
- “How language-generation AIs could transform science” – not necessarily for the better…
"But the algorithmic summaries could make errors, include outdated information or remove nuance and uncertainty, without users appreciating this. If anyone can use LLMs to make complex research comprehensible, but they risk getting a simplified, idealized view of science that’s at odds with the messy reality, that could threaten professionalism and authority. It might also exacerbate problems of public trust in science."Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
- Definitely sign up for the new Andrew Ng course!
- And then for more light-hearted fun:
Covid Corner
Apparently Covid is over – certainly there are very limited restrictions in the UK now
- The latest results from the ONS tracking study estimate 1 in 60 people in England have Covid. This is at least moving in the right direction compared to couple of weeks ago, when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
Updates from Members and Contributors
- Mani Sarkar has released what looks to be another excellent tutorial and repo, this time on chatbot conversations
- Prithwis De has a new and very topical publication in IEEE: “Multivariate Regression Analysis of Investments by Banks in Fossil Fuel Sectors to Predict Climate Change Consequences“
- Jencir Lee has published the first release of his Time Series Terminal – more details at https://tsterm.com and also the white paper with promising research results here
- Marco Gorelli has been successful in the recent M6 forecasting competition – very impressive!
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
- EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
- AstraZeneca are looking for a Data Science and AI Engagement lead – more details here
- Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS
