

Hi everyone-
Another month flies by, and although we had that rarest of occasions in the UK – a sunny Easter weekend – the news in general continues to be depressing: law breakers at the highest ranks of government, covid infections high, and of course the devastating war in Ukraine. Hopefully the data science reading materials below might distract a little…
Following is the May edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. Check out our new ‘Jobs!’ section… an extra incentive to read to the end!
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science May 2022 Newsletter
RSS Data Science Section
Committee Activities
We have all been shocked and saddened by events in the Ukraine and our thoughts and best wishes go out to everyone affected
Committee members continue to be actively involved in a joint initiative between the RSS and various other bodies (The Chartered Institute for IT (BCS), the Operational Research Society (ORS), the Royal Academy of Engineering (RAEng), the National Physical Laboratory (NPL), the Royal Society and the IMA (The Institute of Mathematics and its Applications)) in defining standards for data scientist accreditation, with a plan to launch the Advanced Certificate in the summer.
Florian Ostmann (Head of AI Governance and Regulatory Innovation at The Alan Turing Institute) continues to work on setting up the AI Standards Hub pilot. As set out in the previously shared announcement, this new initiative aims to promote awareness and understanding of the role of technical standards as an AI governance and innovation mechanism, and to grow UK stakeholder involvement in international AI standardisation efforts. The AI Standards Hub team have set up an online form to sign up for updates about the initiative (including a notification when the newly developed AI Standards Hub website goes live) and an opportunity to provide feedback to inform the Hub’s strategy. The form can be accessed at www.aistandardshub.org. If you are interested to learn more about the initiative, you can also watch a recording of the recent AI UK session about the AI Standards Hub here.
The RSS has a number of annual awards – nominations for next year are open. It would be fantastic to have more data scientist nominations, particularly for the David Cox Research prize, or maybe an Honorary Fellowship. Suggestions most welcome – post here!
The next RSS DMC (Discussion Meetings Committee) is holding their next Discussion Meeting on 11th May 3-5pm BST held online (with the DeMO at 2pm), discussing the paper ‘Vintage Factor Analysis with Varimax Performs Statistical Inference’ – all welcome
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on Mat 11th when Drew Jaegle, (Research Scientist at DeepMind in London), will discuss his research on “ Perceivers: Towards General-Purpose Neural Network Architectures“. Videos are posted on the meetup youtube channel – and future events will be posted here.
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics…
Bias, ethics and diversity continue to be hot topics in data science…
- We’ve discussed previously the increasing ease with which realistic ‘fakes’ (profiles, images, videos…) can be generated. It’s quite hard to estimate the scale of the problem though, as we are likely increasingly unaware of most instances we come across. Two Stanford University researchers have attempted to shed some light, uncovering over 1,000 AI-generated LinkedIn faces across 70 different businesses:
"It's not a story of mis- or disinfomation, but rather the intersection of a fairly mundane business use case w/AI technology, and resulting questions of ethics & expectations. What are our assumptions when we encounter others on social networks? What actions cross the line to manipulation"- Often, biases in AI models come from under-represented segments in the training data used to generate the model. And often a good way of countering this problem is by really digging into the underlying data and augmenting those under-represented segments – good case study on Native Americans from the NYTimes . (If anyone is interested in further background on bias, there is always the 86 page NIST Special Publication 1270: Towards a Standard for Identifying and Managing Bias in Artificial Intelligence)
"The image recognition app botched its task, Mr. Monteith said, because it didn’t have proper training data. Ms. Edmo explained that tagging results are often “outlandish” and “offensive,” recalling how one app identified a Native American person wearing regalia as a bird. And yet similar image recognition apps have identified with ease a St. Patrick’s Day celebration, Ms. Ardalan noted as an example, because of the abundance of data on the topic."- Under-representation of minority groups is a key challenge for the US Census, which is a critical problem as many government decisions (from voting districts to funding) are based on the census figures. Excellent Wired article digging into these challenges and whether ML approaches to understanding satellite imagery can help.
- Research from Facebook/Meta attempting to counter the imbalance in wikipedia coverage by automatically generating basic wikipedia entries for those who are under-represented…
"While women are more likely to write biographies about other women, Wikimedia’s Community Insights 2021 Report, which covers the previous year, found that only 15 percent of Wikipedia editors identified as women. This leaves women overlooked and underrepresented, despite the enormous impact they’ve had throughout history in science, entrepreneurship, politics, and every other part of society."- In terms of ethical use cases for AI – I’m not sure about this one… “Companies are using AI to monitor your mood during sales calls“
- AI is increasingly helping drug discovery, pinpointing new compounds and structures with potential for tackling known health problems. However, could this process be driven in the other direction, identifying harmful compounds for use in BioWeapons… the Spiez Lab in Switzerland thinks so in this nature paper – more commentary here
- Good interview with Timnit Gebru and Alex Hanna on DAIR and the ‘Slow AI Movement’
"These modes of research require organizations that can gather a lot of data, data that is often collected via ethically or legally questionable technologies, like surveilling people in nonconsensual ways. If we want to build technology that has meaningful community input, then we need to really think about what’s best. Maybe AI is not the answer for what some particular community needs."- Interesting paper from the Center for the Governance of AI, advocating for more access to the foundational models being generated.
"We argue that for the NAIRR to meet its goal of supporting non-commercial AI research, its design must take into account what we predict will be another closely related trend in AI R&D: an increasing reliance on large pre-trained models, accessed through application programming interfaces (APIs)."- Finally some commentary and a more in depth review (from the Ada Lovelace Institute) of the European Commission proposal for the Artificial Intelligence Act (‘the AI Act’)
"An analysis of the Act for the U.K.-based Ada Lovelace Institute by a leading internet law academic, Lilian Edwards, who holds a chair in law, innovation and society at Newcastle University, highlights some of the limitations of the framework — which she says derive from it being locked to existing EU internal market law; and, specifically, from the decision to model it along the lines of existing EU product regulations."Developments in Data Science…
As always, lots of new developments on the research front and plenty of arXiv papers to read…
- Recently, Google has been crushing it on the research front!
- Matrix Factorisation is still a very useful and efficient approach to a number of ML tasks (e.g. collaborative filtering for recommender systems). Scaling has been a problem in the past, but maybe not so much anymore…“Large Scale Matrix Factorisation on TPUs”
- One of the challenges with Reinforcement Learning is how to initialise the system in the most efficient way (where to start…) – DeepMind have been working on elegantly combing prior expert assumptions with efficient search approaches
- Good progress on making Graph Neural Networks more robust (Twitter have also published research addressing a similar problem)
- You can’t build large language models without incredible amounts of compute power – something we have covered previously that puts this type of research out of the reach of most people. But you also can’t do it without data – and Google have at least helped a little in this space by releasing CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus (dated 1st April but I’m pretty sure it’s not an April Fool…)
- And Deep Mind have been investigating what the optimal language model and dataset size should be given a compute budget… (TL;DR for every doubling of model size the training dataset size should also be doubled)
- Of course the mothership shows what can be done if you have all the compute and data you need… Properly groundbreaking… pushing the boundaries in NLP with the 540 Billion parameter Pathways Language Model (PaLM) And it’s efficient as well- apparently needing ‘only’ 456 megawatt hours to train compared to the 1287 required for GPT-3.
"We evaluated PaLM on 29 widely-used English natural language processing (NLP) tasks. PaLM 540B surpassed few-shot performance of prior large models, such as GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla, and LaMDA, on 28 of 29 of tasks that span question-answering tasks (open-domain closed-book variant), cloze and sentence-completion tasks, Winograd-style tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and natural language inference tasks."- Interestingly, China is increasingly competitive in the large language model space, with recent public announcements of a path to ‘brain-scale’ AI
- ML models typically produce an answer, but getting a feel for the confidence we should have an the answer, or a confidence range around it, is often difficult – useful paper looking into uncertainties
- On this theme, I’m a fan of quantile regression for understanding a distribution of outcomes, not just a point estimate. Promising research from Amazon in this area
- Many ML approaches use regularisation as well as data augmentation to try and prevent over-fitting and improve generalisation- research from Meta/Facebook highlighting how important it is to assess the effects at a class level (as well as overall)
"Those results demonstrate that our search for ever
increasing generalization performance -averaged over all classes and samples- has left us with models
and regularizers that silently sacrifice performances on some classes. This scenario can become dangerous when deploying a model on downstream tasks"- I’m always paranoid about overfitting models, and intrigued by phenomena such as double decent, where, on very large data sets, you can find test set performance improve long after you think you have trained too far. OpenAI have been exploring similar phenomena on smaller data sets (‘Grokking’ – paper here) which could be very powerful.
- This is pretty amazing – DiffusionClip from Korea Advanced Institute of Science and Technology: “zero shot image manipulation guided by text prompts”! And you can play around with it in pyTorch – repo here

- I still struggle getting Deep Learning techniques to perform well (or better than tree based approaches) on traditional tabular data – useful survey on this topic here, and again good to see the repo here
- Does AI make human decision making better? Yes, it looks like. Interesting analysis: using AlphaGo to evaluate Go player moves before and after the release of the system from DeepMind.
"Our analysis of 750,990 moves in 25,033 games by 1,242 professional players reveals that APGs significantly improved the quality of the players’ moves as measured by the changes in winning probability with each move. We also show that the key mechanisms are reductions in the number of human errors and in the magnitude of the most critical mistake during the game. Interestingly, the improvement is most prominent in the early stage of a game when uncertainty is higher"- Fun with equations….”Deep Symbolic Regression for Recurrent Sequences”
"In this paper, we train Transformers
to infer the function or recurrence relation underlying sequences of integers or oats, a typical task in
human IQ tests which has hardly been tackled in the
machine learning literature. We evaluate our integer
model on a subset of OEIS sequences, and show that it
outperforms built-in Mathematica functions for recurrence prediction"Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
- Not to be outdone by Google, OpenAI released DALL-E 2 providing some jaw-dropping examples of generating realistic images from text prompts
- Some excellent commentary from TheVerge here including:
– details of some of the new features like ‘in-painting’ (allowing editing of pictures);
– how it works (building on and improving CLIP – similar to the DiffusionCLIP paper discussed above);
– and also some of the safeguards built in in an attempt to prevent miss-use (“As a preemptive anti-abuse feature, the model also can’t generate any recognisable faces based on a name “) - A dig into how it performs from LessWrong here: some amazing examples although best to steer clear of text and smaller objects
- Some excellent commentary from TheVerge here including:
"Overall this is more powerful, flexible, and accurate than the previous best systems. It still is easy to find holes in it, with with some patience and willingness to iterate, you can make some amazing images."
- In terms of real world impact, DeepMind’s AlphaFold’s ability to predict protein structures has already proven hugely beneficial, and it seems we are only just scratching the surface of its potential – good paper in Nature
“AlphaFold changes the game,” says Beck. “This is like an earthquake. You can see it everywhere,” says Ora Schueler-Furman, a computational structural biologist at the Hebrew University of Jerusalem in Israel, who is using AlphaFold to model protein interactions. “There is before July and after.”- Medical image diagnostics seems like a natural fit for many of the image based AI techniques. There have been lots of positive studies but challenges getting the systems into widespread use. This feels like a positive step – official certification for Oxipit’s autonomous AI imaging suite
- This feels a little far-fetched but potentially very useful- detecting heart problems from the sound of your voice
- We’ve previously had “Pig grunts reveal their emotions“… now … wait for it … it’s the mushrooms who doing the are talking…
- What looks like a powerful approach for earthquake detection, using Deep Learning to filter out city noise
"When applied to the data sets taken from the Long Beach area, the algorithms detected substantially more earthquakes and made it easier to work out how and where they started. And when applied to data from a 2014 earthquake in La Habra, also in California, the team observed four times more seismic detections in the “denoised” data compared with the officially recorded number."- Feels like a very positive use-case: using ML techniques to optimise the cost-effective production of algae based bio-fuels
- Are animators’ jobs the next in line for AI replacement? Ubisoft has unveiled ‘ZooBuilder’ which “recreates accurate animated skeletons of various animals by analysing video footage”.
- Fully autonomous vehicles risk becoming the next Nuclear Fusion… always on the horizon but never quite realised. Waymo (Google’s subsidiary) announced a significant step though with their testing in San Fransisco
"This morning in San Francisco, a fully autonomous all-electric Jaguar I-PACE, with no human driver behind the wheel, picked up a Waymo engineer to get their morning coffee and go to work. Since sharing that we were ready to take the next step and begin testing fully autonomous operations in the city, we’ve begun fully autonomous rides with our San Francisco employees. They now join the thousands of Waymo One riders we’ve been serving in Arizona, making fully autonomous driving technology part of their daily lives."- And it’s been a month or two since our last ‘slightly scary robot dog’ video… so here we go. This time learning to run very fast using a completely new (and ungainly running technique)
"Yeah, OK, what you’re looking at in the video above isn’t the most graceful locomotion. But MIT scientists announced last week that they got this research platform, a four-legged machine known as Mini Cheetah, to hit its fastest speed ever—nearly 13 feet per second, or 9 miles per hour—not by meticulously hand-coding its movements line by line, but by encouraging digital versions of the machine to experiment with running in a simulated world"How does that work?
A new section on understanding different approaches and techniques
- Contrastive learning is pretty cool- it trains models on the basis of the relationships between examples rather than the examples themselves and underpins some of the recent advances in learning visual representations (e.g. DALL-E, CLIP). But how does it work?- good tutorial here
- How do Graph Neural Networks actually work? Excellent detailed tutorial here complete with fun hand-drawn diagrams…
- This is very elegant – an in-browser visualisation of neural net activations, definitely worth playing around with
"While teaching myself the basics of neural networks, I was finding it hard to bridge the gap between the foundational theory and a practical "feeling" of how neural networks function at a fundamental level. I learned how pieces like gradient descent and different activation functions worked, and I played with building and training some networks in a Google Colab notebook.
Despite the richness of the ecosystem and the incredible power of the available tools, I felt like I was missing a core piece of the puzzle in my understanding."- Solid step by step discussion on building an end to end recommender system – although high level, no code.
- Some useful primers on probability and stats:
"The paper, which was inspired by a short comment in McElreath's book (first edition), shows that theta does not necessarily change much even if you get a significant result. The probability theta can change dramatically under certain conditions, but those conditions are either so stringent or so trivial that it renders many of the significance-based conclusions in psychology and psycholinguistics questionable at the very least."- Finally, if you are a data scientist, you are using git (or something similar) for your code repository … “Comprehensive Guide to GitHub for Data Scientists“
Practical tips
How to drive analytics and ML into production
- Best practices for structuring data science work (to make collaboration and upkeep easier) are very useful. This seems like sensible approach here. Similar theme here as well ( “Everything gets a package? Yes, everything gets a package.”) – both seem to leverage Cookiecutter Data Science
"It's no secret that good analyses are often the result of very scattershot and serendipitous explorations. Tentative experiments and rapidly testing approaches that might not work out are all part of the process for getting to the good stuff, and there is no magic bullet to turn data exploration into a simple, linear progression.
That being said, once started it is not a process that lends itself to thinking carefully about the structure of your code or project layout, so it's best to start with a clean, logical structure and stick to it throughout. We think it's a pretty big win all around to use a fairly standardized setup like this one." - Why python has become the lingua franca of data science (and scientific computing): speed vs agility
- Data lineage is hard to do, but so useful if you can get it working well.
- Data Exchange podcast with Wendy Foster on Data Science at Shopify – useful tips on team structure and project organisation
- Entertaining discussion on Reddit about how to chose the right ML algorithm for your problem- I rather like the “no free lunch” theorem mentioned!
- Great post from the team at Etsy on imbalance detection in A/B testing
"Despite their conceptual simplicity, A/B tests are complex to implement, and flawed setups can lead to incorrect conclusions. One problem that can arise in misconfigured experiments is imbalance, where the groups being compared consist of such dissimilar user populations that any attempt to credit the feature under test with a change in success metrics becomes questionable."- And finally a few thought provoking posts on visualisation:
"My colleagues Ian Johnson, Mike Freeman, and I recently collaborated on a series of data-driven stories about electricity usage in Texas and California to illustrate best practices of Analyzing Time Series Data. We found ourselves repeatedly changing how we visualized the data to reveal the underlying signals, rather than treating those signals as noise by following the standard practice of aggregating the hourly data to days, weeks, or months. Behind many of the best practices we recommended for time series analysis was a deeper theme: actually embracing the complexity of the data." Bigger picture ideas
Longer thought provoking reads – lean back and pour a drink!
- Physics is often thought to be a great background for data science (I’m biased of course…) but can we use physics based approaches to better understand machine learning? A good read for any physicists out there!
"Why is this viewpoint useful? Because it gives us some hints on why ML works or doesn’t work:
1) ML models don’t just minimize a singular loss functions. Instead, they evolve dynamically. We need to consider the dynamical evolution when thinking about ML.
2) We cannot really understand ML models using just a handle of metrics. They capture the macroscopic but not the microscopic behaviors of the model. We should think of metrics as tiny windows into a complex dynamical system, with each metric highlighting just one aspect of our models."- Short and sweet this one – Bad ML Abstractions
- Lecture from Yann LeCun on “A path to human-level intelligence”
- But should we be pursuing that? A much longer read but worth it – “The Turing Trap: The Promise and Peril of Human-Like Artificial Intelligence”
"The benefits of human-like artificial intelligence (HLAI) include soaring productivity, increased leisure, and perhaps most profoundly a better understanding of our own minds. But not all types of AI are human-like–in fact, many of the most powerful systems are very different from humans–and an excessive focus on developing and deploying HLAI can lead us into a trap.""Suppose you’re a robot visiting a carnival, and you confront a fun-house mirror; bereft of common sense, you might wonder if your body has suddenly changed. On the way home, you see that a fire hydrant has erupted, showering the road; you can’t determine if it’s safe to drive through the spray. You park outside a drugstore, and a man on the sidewalk screams for help, bleeding profusely. Are you allowed to grab bandages from the store without waiting in line to pay? ""Very rarely does one actually know the data generating function, or even a reasonable proxy - real world data is disorganized, inconsistent, and unpredictable. As a result, the term “distribution” is vague enough to not address the additional specificity necessary to direct actions and interventions"- A tricky concept well described- the difference between machine learning and traditional algorithms and how they are converging
"Machine learning and traditional algorithms are two substantially different ways of computing, and algorithms with predictions is a way to bridge the two."- Engaging discussion on what problems are worth tackling: “Looking for dragons drives progress“
"The "adjacent possible" is an idea that comes from Stewart Kaufmann and describes how evolutionary systems grow - at any given point you’ve got the set of things that already exist, and the adjacent possible is the set of things that could exist as the next generation from the current possibilities."Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
- Test your knowledge of all things AI and Stats with the this Quiz from UKRI CDT in Foundational AI
- Having trouble sleeping? “AI-Generated Sleep Podcast Urges You to Imagine Pleasant Nonsense“
- “How bad is your streaming music?“
- A bit of visualisation inspiration…
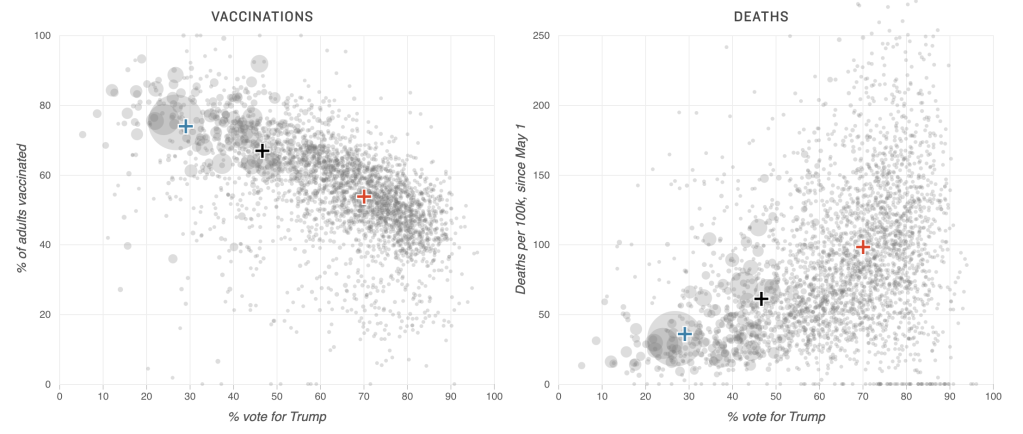
Covid Corner
Apparently Covid is over – certainly there are very limited restrictions in the UK now
- However, no-one told the virus. The latest results from the ONS tracking study estimate 1 in 25 people in England have Covid. This is at least moving in the right direction compared to couple of weeks ago, when it reached 1 in 14… Still a far cry from the 1 in 1000 we had last summer.
- Simple but elegant diagram showing how a new variant may appear milder even with no change in the underlying virulence due to re-infection
- Given all this infection, why don’t we have the much hyped herd immunity?
- One of the challenges throughout the pandemic has been understanding and quantifying the relative risk of Covid to other dangerous things. Useful analysis reported in the NY Times
"For example, she estimated that the average vaccinated and boosted person who was at least 65 years old had a risk of dying after a Covid infection slightly higher than the risk of dying during a year of military service in Afghanistan in 2011"Updates from Members and Contributors
- Ole Schulz-Trieglaff highlights the excellent upcoming PyData London conference (June 17th-19th, 2022)- for those who aren’t aware :
- PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organisation in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.
- NumFOCUS supports many of the most popular data science tools such as pandas and scikit-learn: https://numfocus.org/sponsored-projects
- James Lupino is pleased to announce that RISC AI and IntelliProp have entered into an agreement to cooperate in the in the development of programs, projects and activities related to system integration of processors for Artificial Intelligence (AI) computing in high-speed network fabrics that connect memory, storage and compute resources. More information here. RISC AI do not use gradient descent but a novel method using modal interval arithmetic to guarantee the optimal solution is found in a single run.
Jobs!
A new section highlighting relevant job openings across the Data Science and AI community (let us know if you have anything you’d like to post here…)
- Holisticai, a startup focused on providing insight, assessment and mitigation of AI risk, has a number of relevant AI related job openings- see here for more details
- EvolutionAI, are looking for a machine learning research engineer to develop their award winning AI-powered data extraction platform, putting state of the art deep learning technology into production use. Strong background in machine learning and statistics required
- AstraZeneca are looking for a Data Science and AI Engagement lead – more details here
- Lloyds Register are looking for a data analyst to work across the Foundation with a broad range of safety data to inform the future direction of challenge areas and provide society with evidence-based information.
- Cazoo is looking for a number of senior data engineers – great modern stack and really interesting projects!
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
– Piers
The views expressed are our own and do not necessarily represent those of the RSS

Clearly the robot dog looks ‘scary’ because it doesn’t have a head!
LikeLiked by 1 person